
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- precision #정밀도 #민감도 #sensitivity #특이도 #specifisity #F1 score #dice score #confusion matrix #recall #PR-AUC #ROC-AUC #PR curve #ROC curve #NPV #PPV
- FLOPs #FLOPS
- words encoding
- deep learning #segmentation #sementic #pytorch #UNETR #transformer #UNET #3D #3D medical image
- 데코레이터
- 확산텐서영상
- tqdm #deep learning #dataloader #jupyter #notebook #ipywidgets
- data augmentation #augmentation #3d #deep learning #image # medical image #pytorch #medical #CT #3D
- 코드오류
- PYTHON
- decorater
- 파이썬
- 확산강조영상
- nibabel
- pytorch #torch #ViT #vit #VIT #Transformer #deep learning #vision #classification #image
- RGB #CMYK #DPI
- pytorch #torch #monai #dice #score #metric #segmentation #loss
- MICCAI
- Surgical video analysis
- 유전역학
- nlp
- monai
- MRI
- VNet #Vnet #segmentation #3D #voxel #semantic #pytorch #deep learning #UNet
- genetic epidemiology
- parrec
- nfiti
- TeCNO
- pytorch #torch #torch.nn #torch.nn.Functional #F #nn #차이
- Phase recognition
- Today
- Total
KimbgAI
[ML] ViT(20.10); Vision Transformer 코드 구현 및 설명 with pytorch 본문
[ML] ViT(20.10); Vision Transformer 코드 구현 및 설명 with pytorch
KimbgAI 2022. 11. 10. 15:31AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
https://arxiv.org/pdf/2010.11929.pdf
vit 논문에 관련한 양질의 리뷰는 상당히 많아서, 코드 구현에 관한 설명만 정리하고자 했습니다.
그래도 중요한 특징을 잡고 가자면,
1. 데이터가 많으면 많을수록 성능이 높아진다는 것.
- ImageNet dataset과 같은 Mid-size으로 학습했을때, ResNet보다 성능이 좋지 않았지만, JFT-300M dataset으로 학습할 경우, ResNet보다 좋은 성능 달성함
- 이는 기존 CNN 계열의 모델보다 saturation이 덜 일어난다는 반증.
- 하지만 일반적으로, 큰 데이터셋은 많이 없기때문에, 큰 데이터셋에서 학습된 pretrained model을 transfer learning을 통해 fine tuning을 하는 방식으로 사용된다고 합니다.
2. 이는 곧 Inductive biases가 적다는 것을 의미함.
- Inductive biases란, 학습 알고리즘이 잘 학습할 수 있도록 미리 정의된 가정같은 것입니다.
예를 들면, CNN은 Locality라는 가정을 활용하여 convolution filter 적용하여 공간적인 문제를 풀고, RNN은 Sequentiality라는 가정을 활용해서 순차적인 입력으로 시계열적인 문제를 푸는 것과 같은 맥락입니다.
- 반면에 Transformer 계열은 positional embedding이나 Self-attention 매커니즘을 활용해 receptive field 크기의 한계가
있는 convolution이 아닌 이미지 자체의 모든 정보를 활용하지만 그 정보의 추가적인 가정까지 스스로 추론해야하기 때문에, inductive bias가 부족하여 많은 데이터가 필요하다는 것입니다.
코드 구현 및 설명
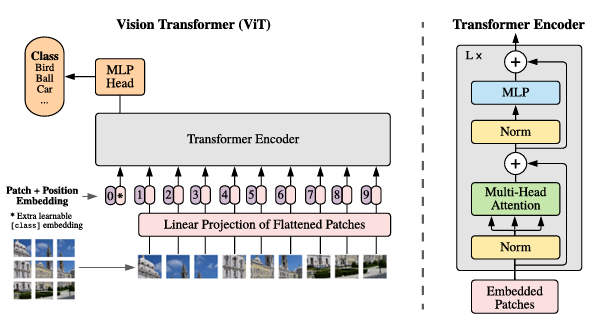
아키텍처는 아래 그림과 같습니다
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary
1. Project input to patches
입력 이미지를 패치로 나누어줍니다
## input ##
x = torch.randn(8, 3, 224, 224)
print('x :', x.shape)
patch_size = 16 # 16x16 pixel patch
patches = rearrange(x, 'b c (h s1) (w s2) -> b (h w) (s1 s2 c)',
s1=patch_size, s2=patch_size)
print('patches :', patches.shape)x : torch.Size([8, 3, 224, 224])
patches : torch.Size([8, 196, 768])위와 같이 rearrange를 통해 단순히 reshape을 해줄수 있지만, 아래와 같이 Conv이용해 패치를 구성하면 성능 이점이 있다고 합니다.
patch_size = 16
in_channels = 3
emb_size = 768 # channel * patch_size * patch_size
# using a conv layer instead of a linear one -> performance gains
projection = nn.Sequential(
nn.Conv2d(in_channels, emb_size,
kernel_size=patch_size, stride=patch_size), # torch.Size([8, 768, 14, 14])
Rearrange('b e (h) (w) -> b (h w) e'))
summary(projection, x.shape[1:], device='cpu')----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 768, 14, 14] 590,592
Rearrange-2 [-1, 196, 768] 0
================================================================
Total params: 590,592
Trainable params: 590,592
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 2.30
Params size (MB): 2.25
Estimated Total Size (MB): 5.12
----------------------------------------------------------------
2. Patches embedding
patches에 class token과 positional embedding을 넣어줍니다.
class token은 어떤 클래스인지 학습하기위한 파라미터이고,
positional은 패치가 어떤 위치에 있는지 알기위한 학습 가능한 파라미터 입니다.
(여담이지만, 개인적으로 class token 없어도 학습이 잘 이루어지는걸 확인했는데, 모델의 마지막 layer인 linear layer에서 모델의 모든 feature들이 계산되는걸 보면 굳이 없어도 되지 않은가 싶었다.)
emb_size = 768
img_size = 224
patch_size = 16
# 이미지를 패치사이즈로 나누고 flatten
projected_x = projection(x)
print('Projected X shape :', projected_x.shape)
# cls_token과 pos encoding Parameter 정의
cls_token = nn.Parameter(torch.randn(1,1, emb_size))
positions = nn.Parameter(torch.randn((img_size // patch_size) **2 + 1, emb_size))
print('Cls Shape :', cls_token.shape, ', Pos Shape :', positions.shape)
# cls_token을 반복하여 배치사이즈의 크기와 맞춰줌
batch_size = 8
cls_tokens = repeat(cls_token, '() n e -> b n e', b=batch_size)
print('Repeated Cls shape :', cls_tokens.shape)
# cls_token과 projected_x를 concatenate
cat_x = torch.cat([cls_tokens, projected_x], dim=1)
# position encoding을 더해줌
cat_x += positions
print('output : ', cat_x.shape)Projected X shape : torch.Size([8, 196, 768])
Cls Shape : torch.Size([1, 1, 768]) , Pos Shape : torch.Size([197, 768])
Repeated Cls shape : torch.Size([8, 1, 768])
output : torch.Size([8, 197, 768])클래스형태로 만들어줌
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16,
emb_size: int = 768, img_size: int = 224):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
# using a conv layer instead of a linear one -> performance gains
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'))
self.cls_token = nn.Parameter(torch.randn(1,1, emb_size))
self.positions = nn.Parameter(torch.randn((img_size // patch_size) **2 + 1, emb_size))
def forward(self, x: Tensor) -> Tensor:
b, _, _, _ = x.shape
x = self.projection(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# prepend the cls token to the input
x = torch.cat([cls_tokens, x], dim=1)
# add position embedding
x += self.positions
return x
PE = PatchEmbedding()
summary(PE, (3, 224, 224), device='cpu')----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 768, 14, 14] 590,592
Rearrange-2 [-1, 196, 768] 0
================================================================
Total params: 590,592
Trainable params: 590,592
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 2.30
Params size (MB): 2.25
Estimated Total Size (MB): 5.12
----------------------------------------------------------------
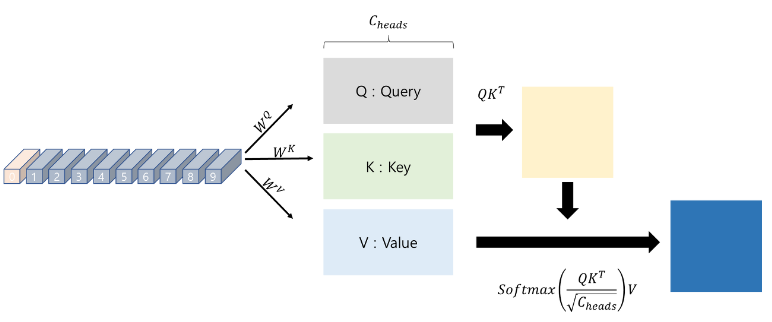
3. Multi Head Attention (MHA)
패치들에 대해 셀프 어텐션 메커니즘을 적용함.
emb_size = 768
num_heads = 8
keys = nn.Linear(emb_size, emb_size)
queries = nn.Linear(emb_size, emb_size)
values = nn.Linear(emb_size, emb_size)
print(keys, queries, values)
x = PE(x)
print(queries(x).shape) # batch, n, emb_size
queries = rearrange(queries(x), "b n (h d) -> b h n d", h=num_heads) # -> batch, head, n, emb_size/head
keys = rearrange(keys(x), "b n (h d) -> b h n d", h=num_heads)
values = rearrange(values(x), "b n (h d) -> b h n d", h=num_heads)
print('shape :', queries.shape, keys.shape, values.shape)Linear(in_features=768, out_features=768, bias=True) Linear(in_features=768, out_features=768, bias=True) Linear(in_features=768, out_features=768, bias=True)
torch.Size([8, 197, 768])
shape : torch.Size([8, 8, 197, 96]) torch.Size([8, 8, 197, 96]) torch.Size([8, 8, 197, 96])# Queries * Keys
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys)
print('energy :', energy.shape)
# Get Attention Score
scaling = emb_size ** (1/2)
att = F.softmax(energy/scaling, dim=-1)
print('att :', att.shape)
# Attention Score * values
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
print('out :', out.shape)
# Rearrage to emb_size
out = rearrange(out, "b h n d -> b n (h d)")
print('out2 : ', out.shape)energy : torch.Size([8, 8, 197, 197])
att : torch.Size([8, 8, 197, 197])
out : torch.Size([8, 8, 197, 96])
out2 : torch.Size([8, 197, 768])1) Key, Query, Value는 모두 같은 값은 인풋으로 받고,
2) linear layer을 통과하여 self-attention이 적용된 후,
3) 스케일링 되고,
4) value와의 연산후 인풋형태와 동일하게 reshape해주어 아웃풋으로 나온다.
이 일련의 과정을 클래스로 묶어줍시다.
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 768, num_heads: int = 8, dropout: float = 0):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
# fuse the queries, keys and values in one matrix
self.qkv = nn.Linear(emb_size, emb_size * 3)
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x : Tensor, mask: Tensor = None) -> Tensor:
# split keys, queries and values in num_heads
qkv = rearrange(self.qkv(x), "b n (h d qkv) -> (qkv) b h n d", h=self.num_heads, qkv=3)
queries, keys, values = qkv[0], qkv[1], qkv[2]
# sum up over the last axis
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
scaling = self.emb_size ** (1/2)
att = F.softmax(energy / scaling, dim=-1)
att = self.att_drop(att)
# sum up over the third axis
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
x = torch.randn(8, 3, 224, 224)
PE = PatchEmbedding()
x = PE(x)
print(x.shape)
MHA = MultiHeadAttention()
summary(MHA, x.shape[1:], device='cpu')torch.Size([8, 197, 768])
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 197, 2304] 1,771,776
Dropout-2 [-1, 8, 197, 197] 0
Linear-3 [-1, 197, 768] 590,592
================================================================
Total params: 2,362,368
Trainable params: 2,362,368
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.58
Forward/backward pass size (MB): 6.99
Params size (MB): 9.01
Estimated Total Size (MB): 16.57
----------------------------------------------------------------
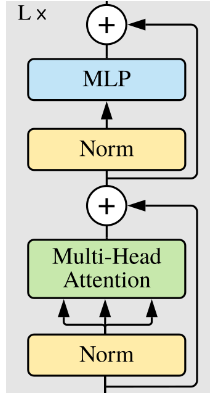
4. Transformer Encoder Block
아래 그림처럼 하나의 블럭으로 만들기 위해,
MLP(feed forward) 블럭을 만들어주고, MHA와 하나로 묶어준다.
class ResidualAdd(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
res = x
x = self.fn(x, **kwargs)
x += res
return x
class FeedForwardBlock(nn.Sequential):
def __init__(self, emb_size: int, expansion: int = 4, drop_p: float = 0.):
super().__init__(
nn.Linear(emb_size, expansion * emb_size),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(expansion * emb_size, emb_size),
)
class TransformerEncoderBlock(nn.Sequential):
def __init__(self,
emb_size: int = 768,
drop_p: float = 0.,
forward_expansion: int = 4,
forward_drop_p: float = 0.,
** kwargs):
super().__init__(
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
MultiHeadAttention(emb_size, **kwargs),
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(
emb_size, expansion=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)
)
))
x = torch.randn(8, 3, 224, 224)
x = PE(x)
x = MHA(x)
TE = TransformerEncoderBlock()
summary(TE, x.shape[1:], device='cpu')----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
LayerNorm-1 [-1, 197, 768] 1,536
Linear-2 [-1, 197, 2304] 1,771,776
Dropout-3 [-1, 8, 197, 197] 0
Linear-4 [-1, 197, 768] 590,592
MultiHeadAttention-5 [-1, 197, 768] 0
Dropout-6 [-1, 197, 768] 0
ResidualAdd-7 [-1, 197, 768] 0
LayerNorm-8 [-1, 197, 768] 1,536
Linear-9 [-1, 197, 3072] 2,362,368
GELU-10 [-1, 197, 3072] 0
Dropout-11 [-1, 197, 3072] 0
Linear-12 [-1, 197, 768] 2,360,064
Dropout-13 [-1, 197, 768] 0
ResidualAdd-14 [-1, 197, 768] 0
================================================================
Total params: 7,087,872
Trainable params: 7,087,872
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.58
Forward/backward pass size (MB): 30.07
Params size (MB): 27.04
Estimated Total Size (MB): 57.69
----------------------------------------------------------------ViT에는 이런 Encoder block이 12개가 있다.
5. 마지막으로 다 묶어서 ViT 빌드
classification을 위한 ClassificationHead 만들어 모델의 마지막 단에 넣어준다.
class TransformerEncoder(nn.Sequential):
def __init__(self, depth: int = 12, **kwargs):
super().__init__(*[TransformerEncoderBlock(**kwargs) for _ in range(depth)])
class ClassificationHead(nn.Sequential):
def __init__(self, emb_size: int = 768, n_classes: int = 1000):
super().__init__(
Reduce('b n e -> b e', reduction='mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes))
class ViT(nn.Sequential):
def __init__(self,
in_channels: int = 3,
patch_size: int = 16,
emb_size: int = 768,
img_size: int = 224,
depth: int = 12,
n_classes: int = 1000,
**kwargs):
super().__init__(
PatchEmbedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassificationHead(emb_size, n_classes)
)
summary(ViT(), (3, 224, 224), device='cpu')----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 768, 14, 14] 590,592
Rearrange-2 [-1, 196, 768] 0
PatchEmbedding-3 [-1, 197, 768] 0
LayerNorm-4 [-1, 197, 768] 1,536
Linear-5 [-1, 197, 2304] 1,771,776
Dropout-6 [-1, 8, 197, 197] 0
Linear-7 [-1, 197, 768] 590,592
MultiHeadAttention-8 [-1, 197, 768] 0
===========================(중략)==============================
Dropout-170 [-1, 197, 768] 0
ResidualAdd-171 [-1, 197, 768] 0
Reduce-172 [-1, 768] 0
LayerNorm-173 [-1, 768] 1,536
Linear-174 [-1, 1000] 769,000
================================================================
Total params: 86,415,592
Trainable params: 86,415,592
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 364.33
Params size (MB): 329.65
Estimated Total Size (MB): 694.56
----------------------------------------------------------------
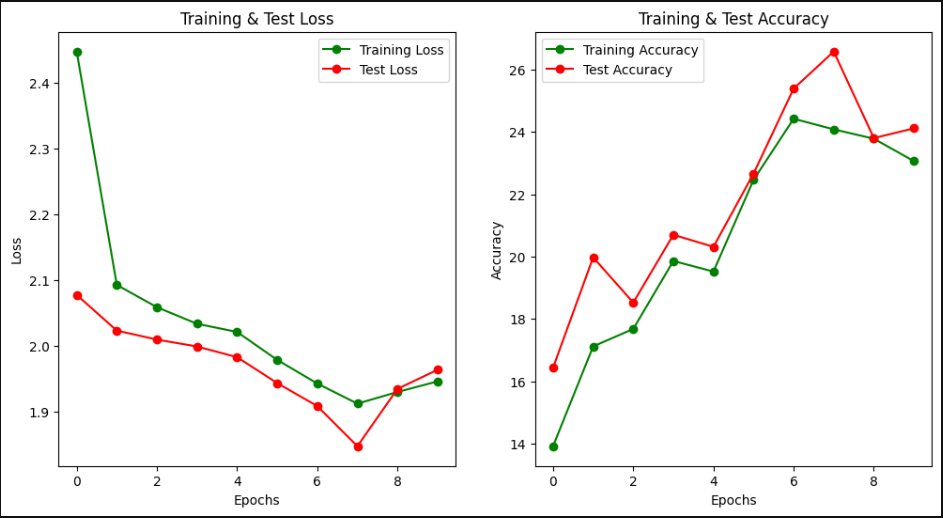
학습결과를 보면, 학습이 상당히 더디다..
STL10 데이터셋으로 간단하게 10에폭정도만 돌려봤다.
학습을 위한 전체코드는 정리가 되면 깃헙에 올려서 링크달아놓겠습니다. :)
아 다른 방식으로 구현한 코드도 있어서, 참고해보셔도 좋을것같습니다.
전체적인 flow는 비슷합니다 ^^
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
from torchsummary import summary
# helpers
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# classes
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 96, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.dropout = nn.Dropout(dropout)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
attn = self.dropout(attn)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls',
channels = 3, dim_head = 96, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)import torch
v = ViT(
image_size = 224,
patch_size = 16,
num_classes = 1000,
dim = 768,
depth = 12,
heads = 8,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
summary(v, (3,224,224), device='cpu')----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Rearrange-1 [-1, 196, 768] 0
Linear-2 [-1, 196, 768] 590,592
Dropout-3 [-1, 197, 768] 0
LayerNorm-4 [-1, 197, 768] 1,536
Linear-5 [-1, 197, 2304] 1,769,472
Softmax-6 [-1, 8, 197, 197] 0
Dropout-7 [-1, 8, 197, 197] 0
Linear-8 [-1, 197, 768] 590,592
Dropout-9 [-1, 197, 768] 0
Attention-10 [-1, 197, 768] 0
PreNorm-11 [-1, 197, 768] 0
LayerNorm-12 [-1, 197, 768] 1,536
Linear-13 [-1, 197, 2048] 1,574,912
GELU-14 [-1, 197, 2048] 0
Dropout-15 [-1, 197, 2048] 0
Linear-16 [-1, 197, 768] 1,573,632
Dropout-17 [-1, 197, 768] 0
FeedForward-18 [-1, 197, 768] 0
===========================(중략)==============================
Transformer-196 [-1, 197, 768] 0
Identity-197 [-1, 768] 0
LayerNorm-198 [-1, 768] 1,536
Linear-199 [-1, 1000] 769,000
================================================================
Total params: 67,501,288
Trainable params: 67,501,288
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 352.36
Params size (MB): 257.50
Estimated Total Size (MB): 610.43
----------------------------------------------------------------
끝!
출처
https://kmhana.tistory.com/27
https://robot-vision-develop-story.tistory.com/29
https://better-tomorrow.tistory.com/entry/Vision-Transformer-ViT-%EC%A0%95%EB%A6%AC-An-Image-is-Worth-16x16-Words-Transformers-for-Image-Recognition-at-Scale
'machine learning' 카테고리의 다른 글
| [ML][pytorch] UNETR(21.03); UNEt TRansformers 코드 설명 및 구현 (2) | 2022.11.21 |
|---|---|
| [ML] Data augmentation for 3D medical image (3) | 2022.11.17 |
| [ML] Dice loss & Dice Score with monai, pytorch (0) | 2022.11.08 |
| [ML][pytorch] torch.nn 과 torch.nn.Functional 의 차이 (0) | 2022.11.08 |
| FLOPs란? 딥러닝 연산량에 대해서.. (2) | 2022.11.03 |


