
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
Tags
- paper review
- 비모수적 모델
- tabular
- nibabel
- 유전역학
- words encoding
- parrec
- 확산텐서영상
- deep learning #segmentation #sementic #pytorch #UNETR #transformer #UNET #3D #3D medical image
- precision #정밀도 #민감도 #sensitivity #특이도 #specifisity #F1 score #dice score #confusion matrix #recall #PR-AUC #ROC-AUC #PR curve #ROC curve #NPV #PPV
- MICCAI
- non-parametric model
- monai
- Surgical video analysis
- TabNet
- Phase recognition
- TeCNO
- PYTHON
- 모수적 모델
- decorater
- parer review
- 데코레이터
- parametric model
- 코드오류
- genetic epidemiology
- nlp
- nfiti
- 확산강조영상
- 파이썬
- MRI
Archives
- Today
- Total
목록BERT (1)
KimbgAI
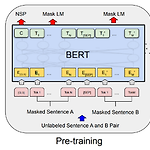 [NLP] BERT에 대한 간단 설명 (paper review)
[NLP] BERT에 대한 간단 설명 (paper review)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018). 2018년에 구글에서 발표된 너무나도 유명하고 NLP 공부할때 milestone이 되는 모델이다. 시작해보자. 개요 언어모델을 개발할때 양질의 pre-trained word representation을 사용하는 것은 매우 중요함. 왜? 좋은 word representation은 down-stream tas..
카테고리 없음
2024. 4. 8. 14:13