
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- nfiti
- parametric model
- 데코레이터
- 모수적 모델
- MICCAI
- TabNet
- decorater
- non-parametric model
- TeCNO
- parrec
- Phase recognition
- paper review
- precision #정밀도 #민감도 #sensitivity #특이도 #specifisity #F1 score #dice score #confusion matrix #recall #PR-AUC #ROC-AUC #PR curve #ROC curve #NPV #PPV
- MRI
- genetic epidemiology
- nlp
- 코드오류
- PYTHON
- parer review
- monai
- 유전역학
- tabular
- words encoding
- deep learning #segmentation #sementic #pytorch #UNETR #transformer #UNET #3D #3D medical image
- nibabel
- Surgical video analysis
- 비모수적 모델
- 확산텐서영상
- 확산강조영상
- 파이썬
- Today
- Total
KimbgAI
[ML] FCN(2014.11); Fully Convolutional Networks for Semantic Segmentation 요약 및 pytorch 코드 구현(2) 본문
[ML] FCN(2014.11); Fully Convolutional Networks for Semantic Segmentation 요약 및 pytorch 코드 구현(2)
KimbgAI 2022. 10. 12. 18:17FCN 모델에 관련된 대략적인 내용은 아래 링크를 통해 확인하시면 되겠습니다. :)
https://kimbg.tistory.com/15?category=578326
[ML] FCN(2014.11); Fully Convolutional Networks for Semantic Segmentation 요약 및 코드 구현
FCN(2014.11); Fully Convolutional Networks for Semantic Segmentation 원문: https://arxiv.org/abs/1411.4038 본 리뷰는 Semantic Segmentation의 기술 동향을 살펴보며, 핵심 아이디어와 Contributions을..
kimbg.tistory.com
본 내용의 구성은 다음과 같다.
1. FCN 구현 방법 2가지 소개
2. 전체 코드 (데이터로드부터 학습 및 결과 확인까지)
(* 본 코드는 FCN32s나 FCN8s가 아니라 모든 maxpooling layer의 output을 활용하였습니다.)
1. FCN 구현 방법 2가지 소개
1) 가장 직관적으로 구현한 코드다.
VGG architecture를 backbone으로 사용하고 중간중간 maxpooling layer의 output을 가져와 사용한다.
하지만 pretrained된 model을 활용하기엔 수정이 필요하다.
import torch
import torch.nn as nn
from torchvision import models
from torchsummary import summary as model_summary
class FCN(nn.Module):
def __init__(self):
super(FCN, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block4 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block5 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, 2, kernel_size=1)
def forward(self, x):
x = self.block1(x)
x1 = x
x = self.block2(x)
x2 = x
x = self.block3(x)
x3 = x
x = self.block4(x)
x4 = x
x = self.block5(x)
x5 = x
score = self.bn1(self.relu(self.deconv1(x5))) # size=(N, 512, x.H/16, x.W/16)
score = score + x4 # element-wise add, size=(N, 512, x.H/16, x.W/16)
score = self.bn2(self.relu(self.deconv2(score))) # size=(N, 256, x.H/8, x.W/8)
score = score + x3 # element-wise add, size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = score + x2 # element-wise add, size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = score + x1 # element-wise add, size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
return score
model = FCN()
model_summary(model, (3,224,224), device='cpu')----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,792
ReLU-2 [-1, 64, 224, 224] 0
Conv2d-3 [-1, 64, 224, 224] 36,928
ReLU-4 [-1, 64, 224, 224] 0
MaxPool2d-5 [-1, 64, 112, 112] 0
Conv2d-6 [-1, 128, 112, 112] 73,856
ReLU-7 [-1, 128, 112, 112] 0
Conv2d-8 [-1, 128, 112, 112] 147,584
ReLU-9 [-1, 128, 112, 112] 0
MaxPool2d-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 295,168
ReLU-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 590,080
ReLU-14 [-1, 256, 56, 56] 0
MaxPool2d-15 [-1, 256, 28, 28] 0
Conv2d-16 [-1, 512, 28, 28] 1,180,160
ReLU-17 [-1, 512, 28, 28] 0
Conv2d-18 [-1, 512, 28, 28] 2,359,808
ReLU-19 [-1, 512, 28, 28] 0
MaxPool2d-20 [-1, 512, 14, 14] 0
Conv2d-21 [-1, 512, 14, 14] 2,359,808
ReLU-22 [-1, 512, 14, 14] 0
Conv2d-23 [-1, 512, 14, 14] 2,359,808
ReLU-24 [-1, 512, 14, 14] 0
MaxPool2d-25 [-1, 512, 7, 7] 0
ConvTranspose2d-26 [-1, 512, 14, 14] 2,359,808
ReLU-27 [-1, 512, 14, 14] 0
BatchNorm2d-28 [-1, 512, 14, 14] 1,024
ConvTranspose2d-29 [-1, 256, 28, 28] 1,179,904
ReLU-30 [-1, 256, 28, 28] 0
BatchNorm2d-31 [-1, 256, 28, 28] 512
ConvTranspose2d-32 [-1, 128, 56, 56] 295,040
ReLU-33 [-1, 128, 56, 56] 0
BatchNorm2d-34 [-1, 128, 56, 56] 256
ConvTranspose2d-35 [-1, 64, 112, 112] 73,792
ReLU-36 [-1, 64, 112, 112] 0
BatchNorm2d-37 [-1, 64, 112, 112] 128
ConvTranspose2d-38 [-1, 32, 224, 224] 18,464
ReLU-39 [-1, 32, 224, 224] 0
BatchNorm2d-40 [-1, 32, 224, 224] 64
Conv2d-41 [-1, 2, 224, 224] 66
================================================================
Total params: 13,334,050
Trainable params: 13,334,050
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 270.46
Params size (MB): 50.87
Estimated Total Size (MB): 321.90
----------------------------------------------------------------2) 이 코드는 torchvision에서 제공하는 pretrained된 VGG를 활용하였다.
import torch
import torch.nn as nn
from torchvision import models
from torchsummary import summary as model_summary
ranges = {'vgg16': ((0, 5), (5, 10), (10, 17), (17, 24), (24, 31))}
class VGGNet(nn.Module):
def __init__(self, pretrained=True):
super(VGGNet, self).__init__()
self.ranges = ranges['vgg16']
self.features = models.vgg16(weights=pretrained).features
def forward(self, x):
output = {}
for idx in range(len(self.ranges)):
for layer in range(self.ranges[idx][0], self.ranges[idx][1]):
x = self.features[layer](x)
output["x%d"%(idx+1)] = x
return output
class FCNs(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5'] # size=(N, 512, x.H/32, x.W/32)
x4 = output['x4'] # size=(N, 512, x.H/16, x.W/16)
x3 = output['x3'] # size=(N, 256, x.H/8, x.W/8)
x2 = output['x2'] # size=(N, 128, x.H/4, x.W/4)
x1 = output['x1'] # size=(N, 64, x.H/2, x.W/2)
score = self.bn1(self.relu(self.deconv1(x5))) # size=(N, 512, x.H/16, x.W/16)
score = score + x4 # element-wise add, size=(N, 512, x.H/16, x.W/16)
score = self.bn2(self.relu(self.deconv2(score))) # size=(N, 256, x.H/8, x.W/8)
score = score + x3 # element-wise add, size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = score + x2 # element-wise add, size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = score + x1 # element-wise add, size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
return score # size=(N, n_class, x.H/1, x.W/1)
vgg16 = VGGNet(pretrained=True)
model = FCNs(vgg16, 2)
model- 먼저 VGGNet를 살펴보면, VGG의 features extractor부분만 가져오고, forward에서 각 maxpooling layer의 output들을 dict형태에 담는다. output만 가져오는게 아니라 저런 형태로 짜여진 이유는 output과 연견된 node graph까지 함께 가져오기 위함이다. output만 단순히 딸랑 가져오게 되면 이전 layer들과의 연결이 끊겨 학습을 할 수가 없다
- pretrained된 vgg16 모델을 FCNs 클래스에 넣어 backbone으로 사용하여 최종 모델을 빌드한다.
2. 전체 코드 (데이터로드부터 학습 및 결과 확인까지)
데이터를 다운받고, 전처리, 로드, 학습, 결과 확인까지 아래의 깃허브에서 확인할 수 있어요.
(ipynb를 여기에 올리려니 너무 번잡스러워서..)
코드 중 데이터가 존재하는 곳으로 root_path만 수정해주시면 됩니다
(torch가 아닌 다른 패키지들이 있을텐데 설치해주세요 monai 등..)
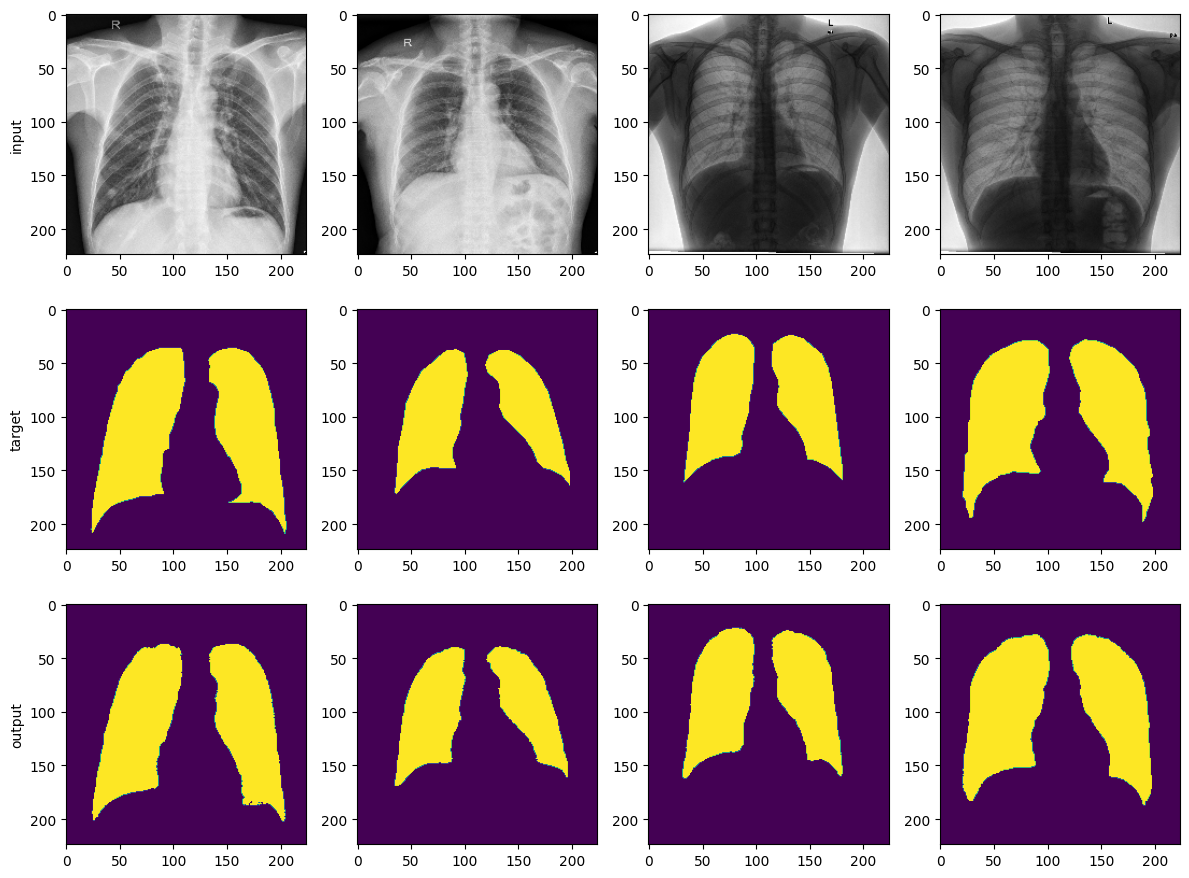
데이터는 kaggle에서 제공하는 Chest X-ray의 폐 영역을 segmentation하는 task에요.
https://github.com/kimbgAI/Segmentation2D
GitHub - kimbgAI/Segmentation2D: 2D Segmentation tutorial with pytorch
2D Segmentation tutorial with pytorch. Contribute to kimbgAI/Segmentation2D development by creating an account on GitHub.
github.com
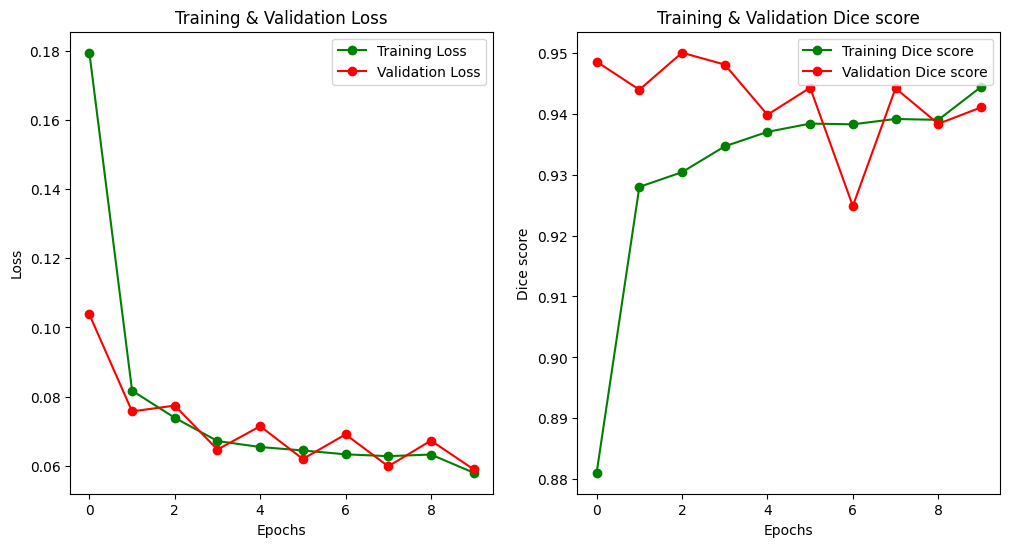
결과만 보자면.. (task가 쉬워서 그런지 생각보다 잘 나오네요?)
끝!



