
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- genetic epidemiology
- 확산강조영상
- paper review
- Phase recognition
- MICCAI
- tabular
- decorater
- parametric model
- 유전역학
- monai
- parrec
- nfiti
- parer review
- words encoding
- MRI
- deep learning #segmentation #sementic #pytorch #UNETR #transformer #UNET #3D #3D medical image
- precision #정밀도 #민감도 #sensitivity #특이도 #specifisity #F1 score #dice score #confusion matrix #recall #PR-AUC #ROC-AUC #PR curve #ROC curve #NPV #PPV
- PYTHON
- nlp
- nibabel
- non-parametric model
- Surgical video analysis
- 데코레이터
- 비모수적 모델
- 모수적 모델
- 파이썬
- 코드오류
- TabNet
- TeCNO
- 확산텐서영상
- Today
- Total
KimbgAI
[ML] VNet(16.06) 요약 및 코드 구현 (pytorch) 본문
V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation
논문은 아래 링크 참조
https://arxiv.org/abs/1606.04797
VNet은 UNet에서 영감을 받아 만들어진 architecture로써 구조가 상당히 비슷하다.
CT나 MRI같은 image sequences data들은 2d보다 3d 그 자체로 분석했을때 유의미한 결과를 얻을 수 있는 부분이 많다.
왜냐하면, 어떤 한 slice 이미지가 직전, 직후 slice 이미지와의 연관성이 매우 높기 때문이다.
3d convolution은 이러한 장점을 가지고 연산할 수 있다. (연산량이 매우 많은 것은 단점..)
그림에서 볼수 있듯이, UNet과 마찬가지로 인코딩과 디코딩 구조에 인코딩 feature map을 사용하여 위취정보의 손실을 줄였다.
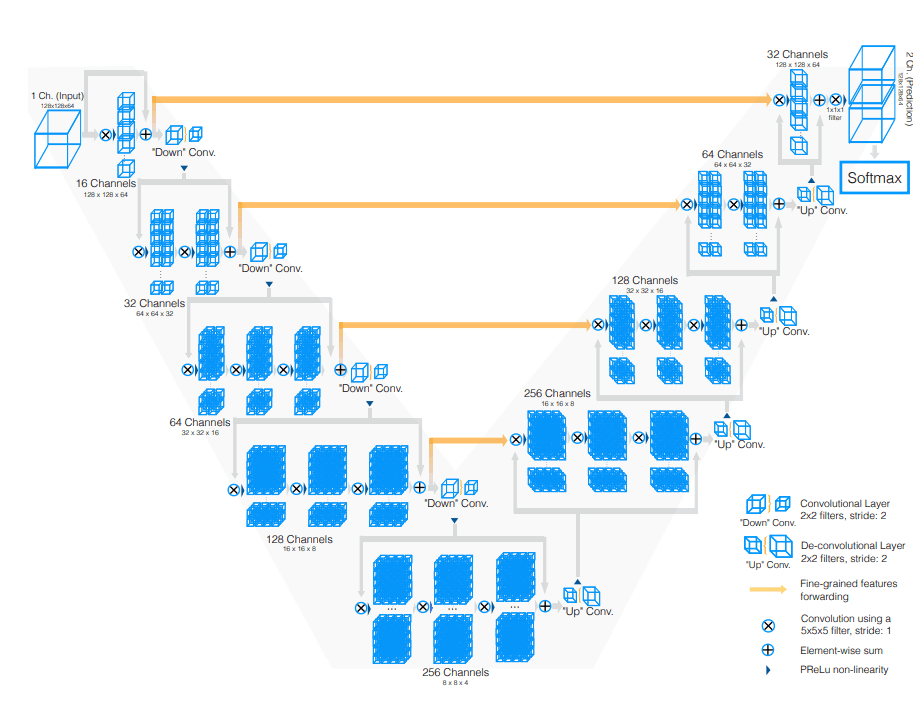
차이점과 핵심 아이디어로는 아래와 같다.
1. 3차원(3D) 형태를 그대로 입출력을 받아 사용하는 아키텍처
- UNet은 input shape이 output shape과 다르다.(input이 더 큼)
2. Dice score를 사용한 loss function
- UNet은 cross entropy를 사용함.
3. Down/Up sampling을 conv 통해 연산
- UNet은 maxpooling을 통해 down sampling을 하였지만, VNet에서는 conv연산을 통해 진행했다.
구현하는 핵심 코드를 살펴보자.
1. 3D convolution은 2D convolution과 크게 다르지 않다. (코드부분에서도)
import torch
import torch.nn as nn
from torchsummary import summaryx = torch.rand((4,1,128,128,128)) #batch, channel, depth, height, width
conv3d_block = nn.Sequential(
nn.Conv3d(x.shape[1], 16, 3, 1, padding=1),
nn.BatchNorm3d(16),
nn.ReLU(),
)
summary(conv3d_block, x.shape[1:], device='cpu')
conv3d_block보시면 아시겠지만 Conv3d를 호출해주면 끝!
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv3d-1 [-1, 16, 128, 128, 128] 448
BatchNorm3d-2 [-1, 16, 128, 128, 128] 32
ReLU-3 [-1, 16, 128, 128, 128] 0
================================================================
Total params: 480
Trainable params: 480
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 8.00
Forward/backward pass size (MB): 768.00
Params size (MB): 0.00
Estimated Total Size (MB): 776.00
----------------------------------------------------------------
Sequential(
(0): Conv3d(1, 16, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1))
(1): BatchNorm3d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
Transpose convolution에서도 마찬가지다.
x = torch.rand((4,1,128,128,128)) #batch, channel, depth, height, width
conv3d_block = nn.Sequential(
nn.ConvTranspose3d(x.shape[1], 16, 2, 2),
nn.BatchNorm3d(16),
nn.ReLU(),
)
summary(conv3d_block, x.shape[1:], device='cpu')
conv3d_block----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
ConvTranspose3d-1 [-1, 16, 256, 256, 256] 144
BatchNorm3d-2 [-1, 16, 256, 256, 256] 32
ReLU-3 [-1, 16, 256, 256, 256] 0
================================================================
Total params: 176
Trainable params: 176
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 8.00
Forward/backward pass size (MB): 6144.00
Params size (MB): 0.00
Estimated Total Size (MB): 6152.00
----------------------------------------------------------------
Sequential(
(0): ConvTranspose3d(1, 16, kernel_size=(2, 2, 2), stride=(2, 2, 2))
(1): BatchNorm3d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
이를 통해 미니 VNet 을 살펴보자면!
아래 코드는 인코딩과 디코딩하는 구조의 흐름을 구현했다고 보시면 되겠습니다.
class MiniVNet(nn.Module):
def __init__(self):
super(MiniVNet, self).__init__()
def EncodingBlock(in_ch, out_ch, ker_size=2, stride=2, padding=1):
layers = []
layers += [nn.Conv3d(in_ch, out_ch, ker_size, stride, padding)]
layers += [nn.BatchNorm3d(out_ch)]
layers += [nn.PReLU()]
return nn.Sequential(*layers)
self.enc1_1 = EncodingBlock(in_ch=1, out_ch=16, ker_size=3, stride=1)
self.down1 = nn.Conv3d(16, 32, kernel_size=2, stride=2)
self.enc2_1 = EncodingBlock(in_ch=32, out_ch=32, ker_size=3, stride=1)
self.enc2_2 = EncodingBlock(in_ch=32, out_ch=32, ker_size=3, stride=1)
self.up2 = nn.ConvTranspose3d(32, 32, kernel_size=2, stride=2)
self.dec1_1 = EncodingBlock(in_ch=32, out_ch=32, ker_size=3, stride=1)
self.conv = nn.Conv3d(32, 3, 1, 1)
def forward(self, x):
enc1_1_res = x
enc1_1 = self.enc1_1(x)
enc1_1 += enc1_1_res
enc2_res = self.down1(enc1_1)
enc2_1 = self.enc2_1(enc2_res)
enc2_2 = self.enc2_2(enc2_1)
enc2_2 += enc2_res
dec1_res = self.up2(enc2_2)
dec1_1 = self.dec1_1(dec1_res)
dec1_1 += dec1_res
outputs = self.conv(dec1_1)
return outputs
model = MiniVNet()
x = torch.rand((4,1,64,128,128))
summary(model, x.shape[1:], device='cpu')
model* forward 부분에서 인코딩의 feature를 디코딩에서 up sampling하여 사용하는 것을 살펴볼 수 있습니다.
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv3d-1 [-1, 16, 64, 128, 128] 448
BatchNorm3d-2 [-1, 16, 64, 128, 128] 32
PReLU-3 [-1, 16, 64, 128, 128] 1
Conv3d-4 [-1, 32, 32, 64, 64] 4,128
Conv3d-5 [-1, 32, 32, 64, 64] 27,680
BatchNorm3d-6 [-1, 32, 32, 64, 64] 64
PReLU-7 [-1, 32, 32, 64, 64] 1
Conv3d-8 [-1, 32, 32, 64, 64] 27,680
BatchNorm3d-9 [-1, 32, 32, 64, 64] 64
PReLU-10 [-1, 32, 32, 64, 64] 1
ConvTranspose3d-11 [-1, 32, 64, 128, 128] 8,224
Conv3d-12 [-1, 32, 64, 128, 128] 27,680
BatchNorm3d-13 [-1, 32, 64, 128, 128] 64
PReLU-14 [-1, 32, 64, 128, 128] 1
Conv3d-15 [-1, 3, 64, 128, 128] 99
================================================================
Total params: 96,167
Trainable params: 96,167
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 4.00
Forward/backward pass size (MB): 1656.00
Params size (MB): 0.37
Estimated Total Size (MB): 1660.37
----------------------------------------------------------------
MiniVNet(
(enc1_1): Sequential(
(0): Conv3d(1, 16, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1))
(1): BatchNorm3d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): PReLU(num_parameters=1)
)
(down1): Conv3d(16, 32, kernel_size=(2, 2, 2), stride=(2, 2, 2))
(enc2_1): Sequential(
(0): Conv3d(32, 32, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1))
(1): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): PReLU(num_parameters=1)
)
(enc2_2): Sequential(
(0): Conv3d(32, 32, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1))
(1): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): PReLU(num_parameters=1)
)
(up2): ConvTranspose3d(32, 32, kernel_size=(2, 2, 2), stride=(2, 2, 2))
(dec1_1): Sequential(
(0): Conv3d(32, 32, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1))
(1): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): PReLU(num_parameters=1)
)
(conv): Conv3d(32, 3, kernel_size=(1, 1, 1), stride=(1, 1, 1))
)
두 가지의 방법으로 구현해보았는데요.
먼저 전부다 풀어쓴 버전입니다.
class VNet(nn.Module):
def __init__(self):
super().__init__()
def EncodingBlock(in_ch, out_ch, ker_size=2, stride=2, padding=1):
layers = []
layers += [nn.Conv3d(in_ch, out_ch, ker_size, stride, padding)]
layers += [nn.BatchNorm3d(out_ch)]
layers += [nn.PReLU()]
return nn.Sequential(*layers)
self.enc1_1 = EncodingBlock(in_ch=1, out_ch=16, ker_size=3, stride=1)
self.expand_ch1 = nn.Conv3d(16, 32, kernel_size=3, stride=1, padding=1)
self.down1 = nn.Conv3d(16, 32, kernel_size=2, stride=2)
self.enc2_1 = EncodingBlock(in_ch=32, out_ch=32, ker_size=3, stride=1)
self.enc2_2 = EncodingBlock(in_ch=32, out_ch=32, ker_size=3, stride=1)
self.expand_ch2 = nn.Conv3d(32, 64, kernel_size=3, stride=1, padding=1)
self.down2 = nn.Conv3d(32, 64, kernel_size=2, stride=2)
self.enc3_1 = EncodingBlock(in_ch=64, out_ch=64, ker_size=3, stride=1)
self.enc3_2 = EncodingBlock(in_ch=64, out_ch=64, ker_size=3, stride=1)
self.enc3_3 = EncodingBlock(in_ch=64, out_ch=64, ker_size=3, stride=1)
self.expand_ch3 = nn.Conv3d(64, 128, kernel_size=3, stride=1, padding=1)
self.down3 = nn.Conv3d(64, 128, kernel_size=2, stride=2)
self.enc4_1 = EncodingBlock(in_ch=128, out_ch=128, ker_size=3, stride=1)
self.enc4_2 = EncodingBlock(in_ch=128, out_ch=128, ker_size=3, stride=1)
self.enc4_3 = EncodingBlock(in_ch=128, out_ch=128, ker_size=3, stride=1)
self.expand_ch4 = nn.Conv3d(128, 256, kernel_size=3, stride=1, padding=1)
self.down4 = nn.Conv3d(128, 256, kernel_size=2, stride=2)
self.enc5_1 = EncodingBlock(in_ch=256, out_ch=256, ker_size=3, stride=1)
self.enc5_2 = EncodingBlock(in_ch=256, out_ch=256, ker_size=3, stride=1)
self.enc5_3 = EncodingBlock(in_ch=256, out_ch=256, ker_size=3, stride=1)
self.up5 = nn.ConvTranspose3d(256, 256, kernel_size=2, stride=2)
self.dec4_1 = EncodingBlock(in_ch=256, out_ch=256, ker_size=3, stride=1)
self.dec4_2 = EncodingBlock(in_ch=256, out_ch=256, ker_size=3, stride=1)
self.dec4_3 = EncodingBlock(in_ch=256, out_ch=256, ker_size=3, stride=1)
self.up4 = nn.ConvTranspose3d(256, 128, kernel_size=2, stride=2)
self.dec3_1 = EncodingBlock(in_ch=128, out_ch=128, ker_size=3, stride=1)
self.dec3_2 = EncodingBlock(in_ch=128, out_ch=128, ker_size=3, stride=1)
self.dec3_3 = EncodingBlock(in_ch=128, out_ch=128, ker_size=3, stride=1)
self.up3 = nn.ConvTranspose3d(128, 64, kernel_size=2, stride=2)
self.dec2_1 = EncodingBlock(in_ch=64, out_ch=64, ker_size=3, stride=1)
self.dec2_2 = EncodingBlock(in_ch=64, out_ch=64, ker_size=3, stride=1)
self.up2 = nn.ConvTranspose3d(64, 32, kernel_size=2, stride=2)
self.dec1_1 = EncodingBlock(in_ch=32, out_ch=32, ker_size=3, stride=1)
self.conv = nn.Conv3d(32, 3, 1, 1)
def forward(self, x):
enc1_1_res = x
enc1_1 = self.enc1_1(x)
enc1_1 += enc1_1_res
enc2_res = self.down1(enc1_1)
enc2_1 = self.enc2_1(enc2_res)
enc2_2 = self.enc2_2(enc2_1)
enc2_2 += enc2_res
enc3_res = self.down2(enc2_2)
enc3_1 = self.enc3_1(enc3_res)
enc3_2 = self.enc3_2(enc3_1)
enc3_3 = self.enc3_3(enc3_2)
enc3_3 += enc3_res
enc4_res = self.down3(enc3_3)
enc4_1 = self.enc4_1(enc4_res)
enc4_2 = self.enc4_2(enc4_1)
enc4_3 = self.enc4_3(enc4_2)
enc4_3 += enc4_res
enc5_res = self.down4(enc4_3)
enc5_1 = self.enc5_1(enc5_res)
enc5_2 = self.enc5_2(enc5_1)
enc5_3 = self.enc5_3(enc5_2)
enc5_3 += enc5_res
dec4_res = self.up5(enc5_3)
enc4_3 = self.expand_ch4(enc4_3)
dec4 = dec4_res + enc4_3
dec4_1 = self.dec4_1(dec4)
dec4_2 = self.dec4_1(dec4_1)
dec4_3 = self.dec4_1(dec4_2)
dec4_3 += dec4_res
dec3_res = self.up4(enc4_3)
enc3_3 = self.expand_ch3(enc3_3)
dec3 = dec3_res + enc3_3
dec3_1 = self.dec3_1(dec3)
dec3_2 = self.dec3_1(dec3_1)
dec3_3 = self.dec3_1(dec3_2)
dec3_3 += dec3_res
dec2_res = self.up3(enc3_3)
enc2_2 = self.expand_ch2(enc2_2)
dec2 = dec2_res + enc2_2
dec2_1 = self.dec2_1(dec2)
dec2_2 = self.dec2_1(dec2_1)
dec2_2 += dec2_res
dec1_res = self.up2(enc2_2)
enc1_1 = self.expand_ch1(enc1_1)
dec1 = dec1_res + enc1_1
dec1_1 = self.dec1_1(dec1)
dec1_1 += dec1_res
outputs = self.conv(dec1_1)
return outputs
model = VNet()
x = torch.rand((4,1,64,128,128))
summary(model, x.shape[1:], device='cpu')
model다소 지저분해보입니다.
EcondingBlock이 중복되어 사용되어 코드를 관리하기에 어려움과 가독성이 떨어질 수 있습니다.
아래는 조금더 깔끔한 코드!
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super().__init__()
self.net = nn.Sequential(
nn.Conv3d(in_channels, out_channels, kernel_size, stride, padding),
nn.BatchNorm3d(out_channels),
nn.PReLU()
)
def forward(self, x):
return self.net(x)
class BigBlock(nn.Module):
def __init__(self, depth, in_channels, out_channels):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(ConvBlock(in_channels, out_channels))
in_channels = out_channels
def forward(self, x):
for l in self.layers:
x = l(x)
return x
class VNet(nn.Module):
def __init__(self):
super().__init__()
self.enc1 = BigBlock(depth=1, in_channels=1, out_channels=16)
self.expand_ch1 = nn.Conv3d(16, 32, kernel_size=3, stride=1, padding=1)
self.down1 = nn.Conv3d(16, 32, kernel_size=2, stride=2)
self.enc2 = BigBlock(depth=2, in_channels=32, out_channels=32)
self.expand_ch2 = nn.Conv3d(32, 64, kernel_size=3, stride=1, padding=1)
self.down2 = nn.Conv3d(32, 64, kernel_size=2, stride=2)
self.enc3 = BigBlock(depth=3, in_channels=64, out_channels=64)
self.expand_ch3 = nn.Conv3d(64, 128, kernel_size=3, stride=1, padding=1)
self.down3 = nn.Conv3d(64, 128, kernel_size=2, stride=2)
self.enc4 = BigBlock(depth=3, in_channels=128, out_channels=128)
self.expand_ch4 = nn.Conv3d(128, 256, kernel_size=3, stride=1, padding=1)
self.down4 = nn.Conv3d(128, 256, kernel_size=2, stride=2)
self.enc5 = BigBlock(depth=3, in_channels=256, out_channels=256)
self.up5 = nn.ConvTranspose3d(256, 256, kernel_size=2, stride=2)
self.dec4 = BigBlock(depth=3, in_channels=256, out_channels=256)
self.up4 = nn.ConvTranspose3d(256, 128, kernel_size=2, stride=2)
self.dec3 = BigBlock(depth=3, in_channels=128, out_channels=128)
self.up3 = nn.ConvTranspose3d(128, 64, kernel_size=2, stride=2)
self.dec2 = BigBlock(depth=2, in_channels=64, out_channels=64)
self.up2 = nn.ConvTranspose3d(64, 32, kernel_size=2, stride=2)
self.dec1 = BigBlock(depth=1, in_channels=32, out_channels=32)
self.conv = nn.Conv3d(32, 3, 1, 1)
def forward(self, x):
enc1_res = x
enc1 = self.enc1(x)
enc1 += enc1_res
enc2_res = self.down1(enc1)
enc2 = self.enc2(enc2_res)
enc2 += enc2_res
enc3_res = self.down2(enc2)
enc3 = self.enc3(enc3_res)
enc3 += enc3_res
enc4_res = self.down3(enc3)
enc4 = self.enc4(enc4_res)
enc4 += enc4_res
enc5_res = self.down4(enc4)
enc5 = self.enc5(enc5_res)
enc5 += enc5_res
dec4_res = self.up5(enc5)
enc4 = self.expand_ch4(enc4)
dec4 = dec4_res + enc4
dec4 = self.dec4(dec4)
dec4 += dec4_res
dec3_res = self.up4(enc4)
enc3 = self.expand_ch3(enc3)
dec3 = dec3_res + enc3
dec3 = self.dec3(dec3)
dec3 += dec3_res
dec2_res = self.up3(enc3)
enc2 = self.expand_ch2(enc2)
dec2 = dec2_res + enc2
dec2 = self.dec2(dec2)
dec2 += dec2_res
dec1_res = self.up2(enc2)
enc1 = self.expand_ch1(enc1)
dec1 = dec1_res + enc1
dec1 = self.dec1(dec1)
dec1 += dec1_res
outputs = self.conv(dec1)
return outputs
model = VNet()
x = torch.rand((4,1,64,128,128))
summary(model, x.shape[1:], device='cpu')
model중복되는 ConvBlock을 BigBlock으로 묶어서 나름 간단하게(?) 구현해보았습니다 ㅎㅎ;;
데이터 준비과정부터 전처리, 학습까지의 정리된 코드를 github에 올려두었습니다!
https://github.com/kimbgAI/Segmentation3D
GitHub - kimbgAI/Segmentation3D
Contribute to kimbgAI/Segmentation3D development by creating an account on GitHub.
github.com
결과만 보자면..
MSD dataset를 활용했는데 복부 CT 에서 spleen(비장) segmentation하는 문제입니다.
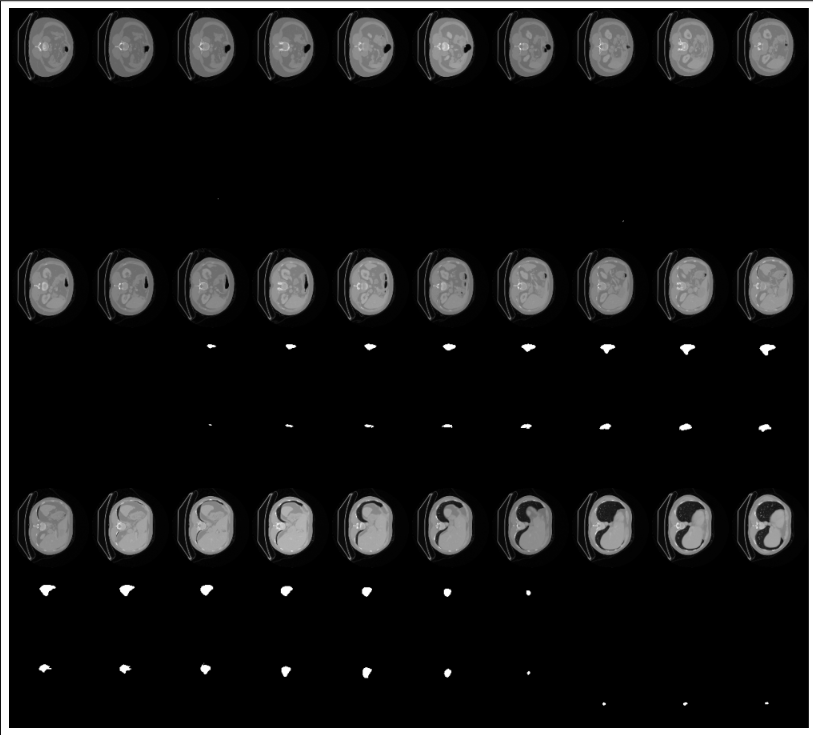
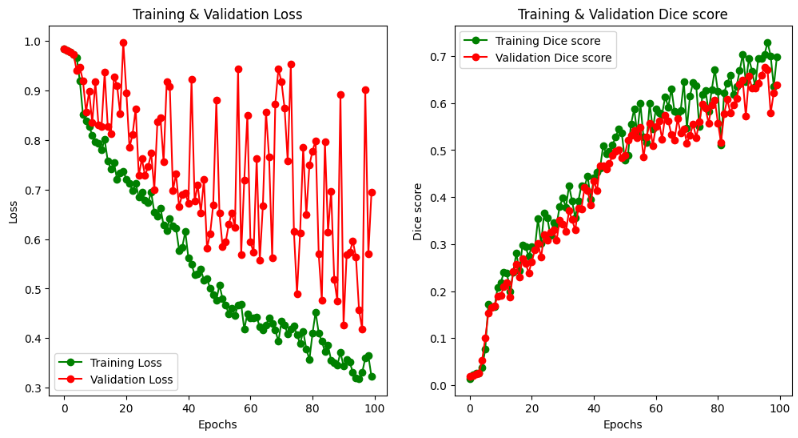
학습이 어느정도 되는구나 확인할 수 있었고,
논문과 implementation detail이 다르다는 점은 참고해주세요!
끝!


