
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- parrec
- 비모수적 모델
- tabular
- 파이썬
- deep learning #segmentation #sementic #pytorch #UNETR #transformer #UNET #3D #3D medical image
- monai
- nibabel
- paper review
- MRI
- 유전역학
- TeCNO
- 코드오류
- parametric model
- 확산텐서영상
- Phase recognition
- 데코레이터
- Surgical video analysis
- PYTHON
- TabNet
- 모수적 모델
- parer review
- non-parametric model
- 확산강조영상
- nlp
- decorater
- genetic epidemiology
- words encoding
- precision #정밀도 #민감도 #sensitivity #특이도 #specifisity #F1 score #dice score #confusion matrix #recall #PR-AUC #ROC-AUC #PR curve #ROC curve #NPV #PPV
- MICCAI
- nfiti
- Today
- Total
KimbgAI
[ML] 분류 평가 지표 정리(sensitivity, recall, precision, specificity, f1 score, NPV, PPV 본문
[ML] 분류 평가 지표 정리(sensitivity, recall, precision, specificity, f1 score, NPV, PPV
KimbgAI 2022. 11. 22. 14:54분류 지표에는 Sensitivity, Precision, Specifisity, PPV, NPV 등.. 여러가지가 있습니다.
모델의 결과를 무엇에 중점을 두고 볼 것인가에 따라 다른 평가 지표를 사용해야하기 때문입니다.
하지만 늘 헷갈리고, 어렴풋이 알고있지만 이게 무엇을 의미하는지 제대로 이해하려면 멈칫하게 되는..
그래서 한번 정리하고자 했습니다.

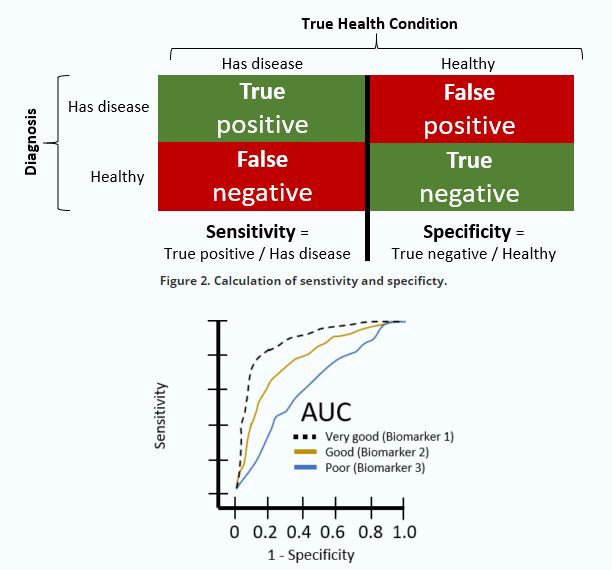
위 그림의 혼동행렬은 주의해서 봐야합니다.
어떤 곳에서는 True class와 Predicted class의 행렬이 뒤바뀌어있는 경우도 있습니다. 실제로 sklearn의 confusion matrix의 결과는 위 그림과는 반대로 행렬이 전치되어 나타납니다.
먼저 민감도.
민감도는 sensitivity, recall 으로도 불립니다.
실제 True 중에서 옳게 예측된 True의 비율입니다.
= (예측True 실제True) / (실제True)
= TP / (TP+FN)
정밀도.
정밀도는 precision, 양성예측도; PPV(Positive predective value) 라고도 불립니다.
예측된 True 중에서 옳게 예측된 True의 비율입니다.
= (예측True 실제True) / (예측True)
= TP / (TP+FP)
* 민감도와 정밀도는 같은 TP(True Positive)를 본다는데는 같지만, 기준을 어디에 두느냐에서 큰 차이가 있습니다.
민감도는 양성(positive)이 critical한 domain에서 모델의 분류가 실제 양성을 놓치지 않도록 평가하기 위함입니다.
실제 양성 중에서 모델이 얼마나 양성을 옳게 예측하느냐가 포인트이기 때문입니다.
반면, 정밀도는 무분별한 양성 예측을 경계하고자 합니다.
모델이 예측한 것 중에서 얼마나 양성을 옳게 예측하느냐가 포인트이기 때문입니다.
그래서 민감도와 정밀도는 trade-off 관계가 있습니다.
민감도를 높히기 위해 decision threshold를 낮춰 양성 예측 비율을 높히게 되면, 무분별한 양성예측으로 정밀도가 내려가기 때문입니다.
이 둘의 적절한 경계를 찾기 위해 보는 평가지표가 바로 F1 score 입니다.
F1 score는 민감도와 정밀도의 조화평균입니다.
* 조화평균은 '역수의 산술평균의 역수'로 계산됩니다.
평균적인 변화율을 구할 때에 주로 사용되고, 조화평균으로 사용하는 이유는 산술평균을 이용하는 것보다, 큰 비중이 끼치는 bias가 줄어들기 때문입니다.
** 한편, F1 score는 dice score와 동치입니다.
일반적인 segmentation task에서 사용되는 dice score는 픽셀별로 class를 구분하는데, 이때 GT(Ground truth)와의 f1 score로 계산됩니다.
한편, 특이도는 specificity 라고도 불립니다.
실제 False 중에서 옳게 예측된 False의 비율입니다.
= (예측False 실제Flase) / (실제False)
= TN / (TN+FP)
(민감도와 비슷하지만 True가 아닌 False 본다는 점입니다.)
또한, 음성예측도; NPV(Negative predicted value)도 있습니다.
예측된 False 중에서 옳게 예측된 False의 비율입니다.
= (예측False 실제False) / (예측False)
= TN / (TN+FN)
(정밀도와 비슷하지만 True가 아닌 False 본다는 점입니다.)
ROC-AUC, PR-AUC
ROC curve는 threshold 변화에 따른 민감도(sensitivity)와 1-specificity의 변화를 나타냅니다.
앞서 설명한것처럼 sensitivity는 실제 True를 중에서 얼마나 옳게 True를 예측했는지,
specificity는 실제 False를 중에서 얼마나 옳게 False를 예측했는지를 나타냅니다.
하지만, 1 - specificity이기 때문에, 실제 False를 중에서 얼마나 틀리게 Positive로 예측했는지를 의미하게됩니다.
따라서 ROC curve는 threshold 가 낮아질수록 민감도(sensitivity)는 높아지고,
그에 따른 False positive도 늘어나기 때문에 1 - specificity도 높아집니다.
ROC curve가 나타내는 아래의 면적을 AUC로 나타내 ROC-AUC라고 부릅니다.
모델이 잘 분류하게 된다면 threshold 변화에 둔감하여 강건하게 분류를 할 수 있음을 나타내고,
이는 곧 ROC-AUC 값이 커지게 됩니다.
한편, PR curve는 threshold 변화에 따른 Precision과 Recall(sensitivity)의 변화를 나타냅니다.
앞서 설명드린것처럼 Precision과 Recall(sensitivity)는 trade-off 관계에 있기 때문에,
Recall(sensitivity)를 높히기 위해 threshold를 낮게 설정하면 Precision는 낮아집니다.
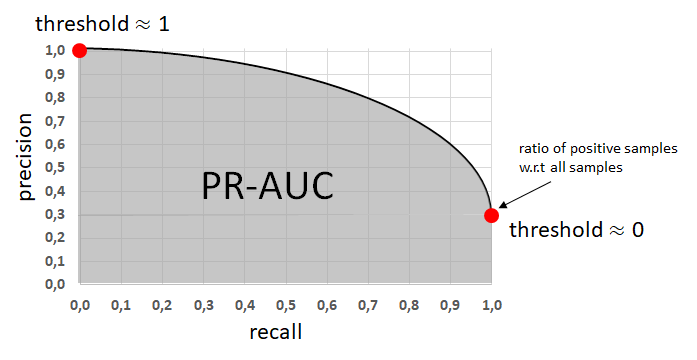
threshold가 0에 가까워 지더라도 precision이 0이 되지 않는 이유는, 당연하게도
threshold가 0 이라면 모든 데이터를 양성으로 예측하게 되는데,
이는 곧 TP / (TP+FP)가 Total positive samples / total sample 가 되기 때문입니다.
즉, 위 그림에서처럼 threshold가 0일때의 precision은 전체 데이터에서 양성 데이터의 비율을 의미하게 됩니다.
끝!
'machine learning' 카테고리의 다른 글
| [오류해결] monai metrics 중 DiceMetric의 y, y_pred 인식 오류 (0) | 2024.03.27 |
|---|---|
| 이미지 내 색상 별 픽셀 수 확인하기 (0) | 2023.03.09 |
| [ML][pytorch] UNETR(21.03); UNEt TRansformers 코드 설명 및 구현 (2) | 2022.11.21 |
| [ML] Data augmentation for 3D medical image (3) | 2022.11.17 |
| [ML] ViT(20.10); Vision Transformer 코드 구현 및 설명 with pytorch (2) | 2022.11.10 |



