
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 데코레이터
- 확산강조영상
- nlp
- 파이썬
- TabNet
- parer review
- nibabel
- Phase recognition
- Surgical video analysis
- parrec
- words encoding
- TeCNO
- paper review
- non-parametric model
- tabular
- genetic epidemiology
- deep learning #segmentation #sementic #pytorch #UNETR #transformer #UNET #3D #3D medical image
- 모수적 모델
- MICCAI
- 확산텐서영상
- decorater
- PYTHON
- parametric model
- 비모수적 모델
- precision #정밀도 #민감도 #sensitivity #특이도 #specifisity #F1 score #dice score #confusion matrix #recall #PR-AUC #ROC-AUC #PR curve #ROC curve #NPV #PPV
- 코드오류
- nfiti
- monai
- MRI
- 유전역학
- Today
- Total
KimbgAI
[medical] 유전역학-개론 1주차, 유전역학 개요 본문
* 주의: 이 글은 수업 내용을 제 나름대로 정리하기 위해 작성한 글입니다.
따라서, 저의 이해를 바탕으로 작성되었기 때문에 부정확한 내용이 있을 수 있습니다.
또한, 정리가 엉망진창일 수 있습니다.. 하하;;
디지털헬스학 이라는 학문을 대학원에서 공부하면서, 대학원의 강의는 일반적으로 수업의 난이도를 스스로 조정할 수 있다는 점에서 함정이 있는 것 같습니다.
디지털헬스학을 대학원에서 전공하시는 동문들을 보면, 그 출신이 굉장히 각양각색인데, 학사 전공이 석사 전공과는 아무 상관이 없는 '경제학'을 전공한 괴짜인 저부터해서 보건, 의료, 의학을 전공하신 진골(?)분들도 있습니다.
아무래도 융합학문의 특성인지라..
그래서 전공 수업들도 자신이 잘 알고 자신있는 수업을 선택해서 고른다면, 그 학기의 시간적 여유와 학점은 대체로 보장받을 수 있더랍니다.
하지만 단점은 너무 순한 맛에 길들여지면, 내가 왜 대학원을 왔는지에 대한 정체성을 잃어버리기 쉽상인데..
그래서 2학기때는 '뇌과학과AI' 라는 수업을 들으면서 뇌과학을 1도 모르는 저로서는 나름 재밌고 알찬 수업이었는데, 아쉬운 것은 '뇌과학'이라는 분야도 너무 방대해서 다양한 연구자들을 모셔 특강을 듣노라면 이해가 되는 부분의 거의 없더라는 겁니다.
아무튼 서론이 길었는데, 이 유전역학을 듣게 된 이유도 크게 다르지 않았습니다.
데이터분석을 공부하고 있는 사람으로서 유전체분석에 대한 관심은 있었는데,
이 또한 하나의 거대한 학문이라 어떻게 뭐부터 시작을 해야할지도 모르겠고.. 막막하고 그랬습니다.
이번 기회에 한번 찍먹해보고자 신청하게 되었고, 수업을 들으니 정말 잘 신청했다는 생각이 들었습니다. 너무 재밌고 교수님께서도 강의에 대한 열의도 넘치시고, 설명도 기가막히기 때문입니다.
내용을 정리하지 않으면 이 귀한 내용을 다 잊어버리겠구나 하는 생각이 들어서, 평소에 하지도 않는 정리를 해봅니다.
=========================================================================================
'유전역학-개론'의 최종 목표는 하나; 유전역학과 관련된 논문을 읽고 이해할 수 있는 것!

1주차는 유전체 역학의 연구의 개요.
2학기에는 유전역학-고급이 있으니, 3학기에 졸업학점을 다 채운 내가 청강생으로 들어갈지도 모르겠다 ㅎㅎ

옛날에는 유전학에 대한 지식도, 기술도 없었기 때문에 어떤 표현형이나 질병에 대해 환경적인 요인에 초점을 두었다.
유전역학은 기본적으로 역학적인 부분이 아닌 유전적인 부분에 대해 초점을 두는 것이고, 병인을 genetic에서 찾는 것이다.

의료 데이터의 종류는 보다시피 엄청 많다.
이 모든 패널에서 변하지 않는 데이터가 단 한가지가 있는데, 그게 바로 Genome data이다.
(다른 데이터들은 시공간에 따라 변화한다)
그렇기 때문에 이 genome data에 대한 분석은 어떤 개체 표본의 기준이 되는 데이터라 볼 수 있다.

Traits이라고 하면, 한 개체의 phenotype과 genotype(ATGC)이라고 할 수 있다.
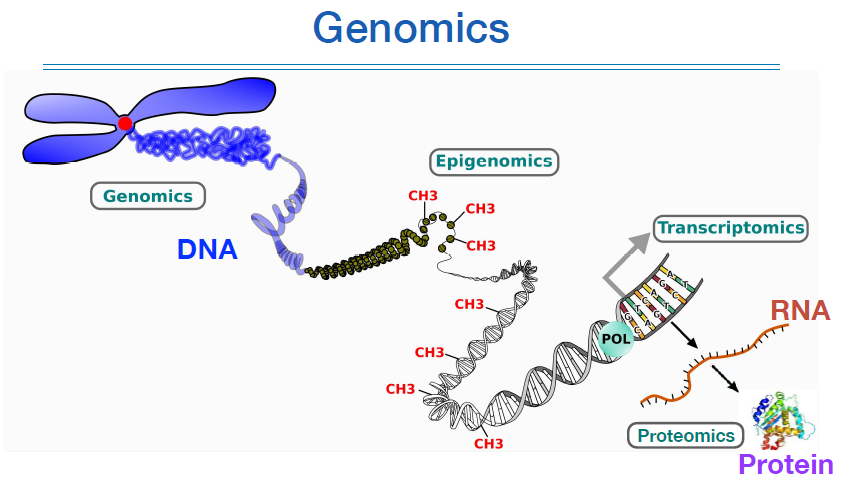
- 어떤 조직내의 실제 action은 DNA에서 발현된 protein이 한다. 이게 핵심.
따라서 염기서열의 variation은 protein의 발현에 영향을 주기 때문에, 특정 action이 발생 유무에 영향을 미칠 수 있다.
DNA -> RNA -> protein -> action
- human genomic variation은 그 자체로 무조건 좋거나 나쁜 것은 아니다. '나'라는 사람의 특성을 만들어주는 것도 variation이기 때문이다.
일반적으로 다른 사람과 나는 1000bp당 1개가 다르다고 알려져있다.
30억개의 염기서열이 있으니, 다른 사람과 나는 300만개가 다른 것이다.
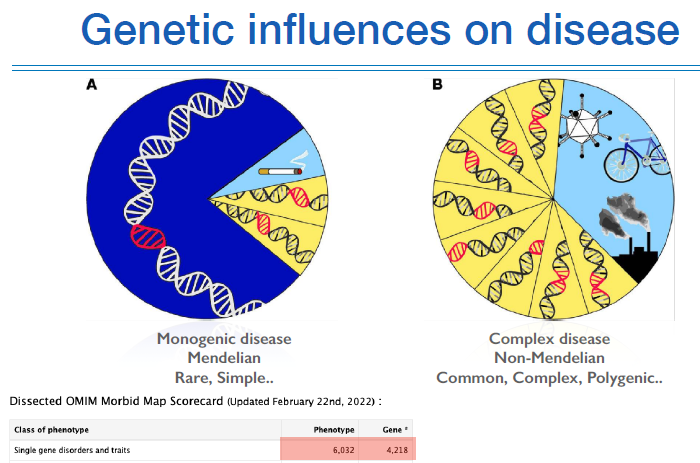
질병에 관여하는 유전적 영향은 크게 2가지로 구분되는데,
Monogenic disease (Mendelian, Rare, Simple)이라고 불리는 것은 어떤 질병에 하나의 유전자가 관여하는 것이고, 환경적인 요인도 크지 않다. 보통 희귀질환이 이에 해당한다.
하지만, Complex disease (Non-mendelian, Common, Polygenic) 은 여러 유전자가 관여하고 환경적인 요인도 비교적 크기때문에 분석하기 어렵고 분석에 많은 case가 요구된다. 암과 같은 일반적인 질환이 이에 해당한다.
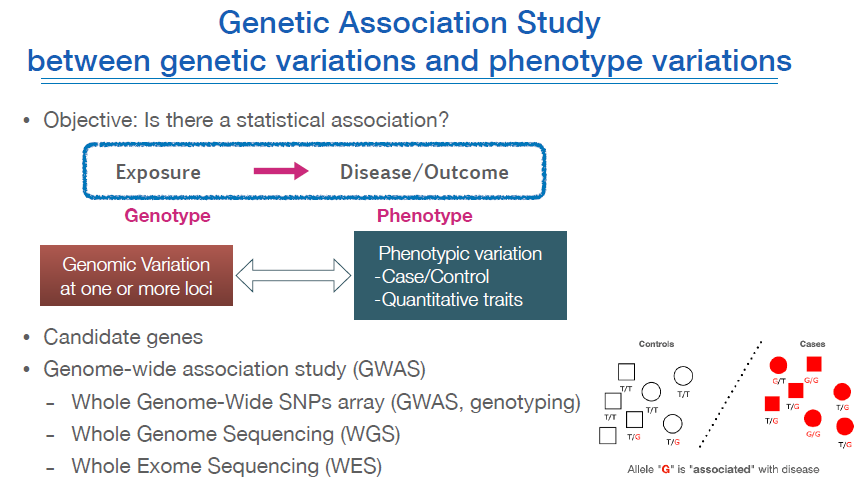
유전 연관 분석은 어떤 genotype이 phenotype과 연관이 있는지 분석하는 것이다.
예를 들면, 파킨슨병에 걸린 사람들의 genotype을 분석해서 어떤 유전자가 이에 관여하는지 알아내는 것이다.
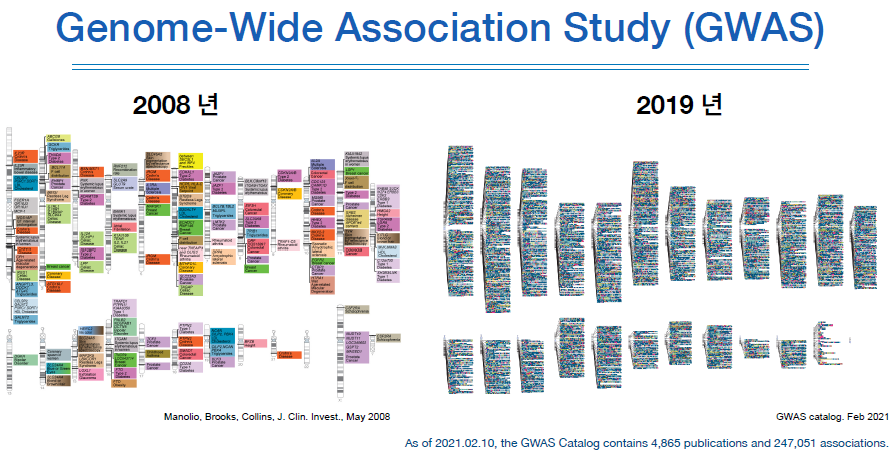
그 이유는 유전체 분석에 드는 비용이 비약적으로 줄어든 것이 한몫했다.
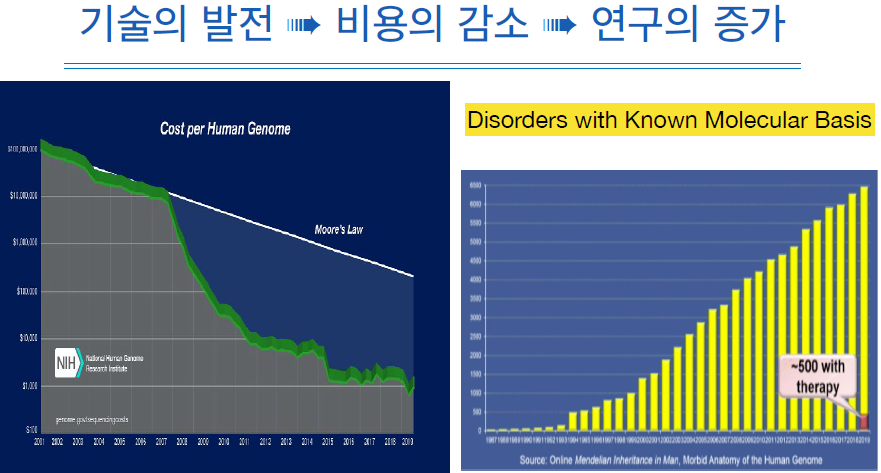
그렇다고 원인 유전자를 알았다고 해서 치료방법을 알아낸 것은 아니니 둘은 서로 다른 이야기이다.
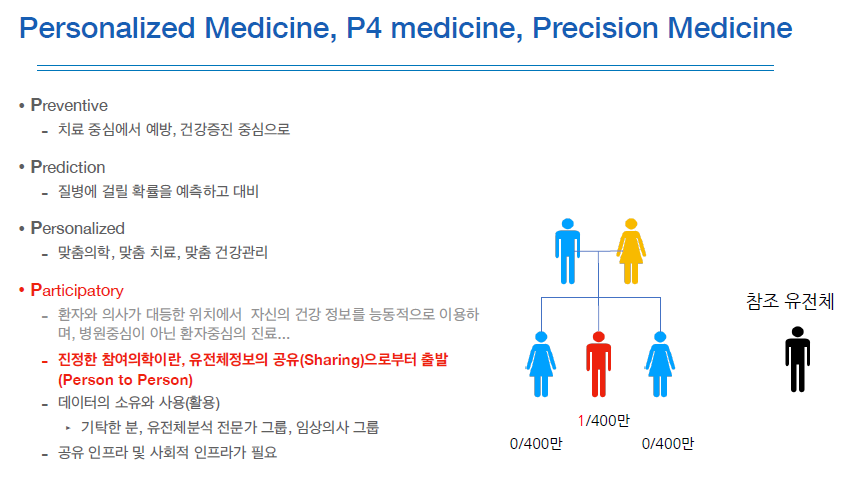
수업 중에 하나를 강조하신 것이 있다.
개인 의료, 정밀 의료 등 개인에 맞춤형 의료 서비스를 나타내는 단어인 P4 medicine이 있었는데,
그 중 Participatory라는 참여의학이라는 개념이다.
참조 유전체와 어떤 rare disease의 genome과의 비교는 400만개의 염기서열이 차이가 난다.
이는 어떤 유전자가 원인인지를 분석하는 유전체분석을 어렵게 만들지만, 친인척들이나 관련 질환을 앓은 사람의 participatory가 있으면 candicate를 상당히 많이 줄일 수 있기 때문에 분석에 많은 도움이 된다.
아래 그림을 보면,
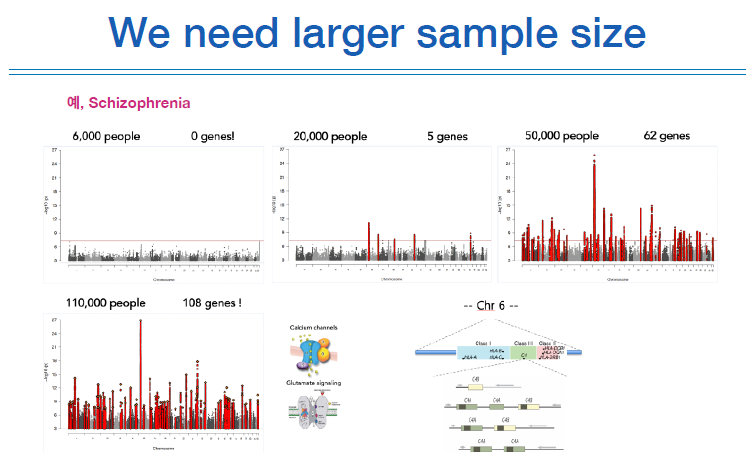
6,000명의 사람에게서 얻은 유전체에서는 유의미한 유전자를 발견하지 못했는데, case가 많이 확보될수록 많은 유전자들를 탐색할 수 있었다.
이런 참여의학과 데이터 공유는 유럽지역에서 상당히 활발히 잘 되고 있다고 한다.
공유, 개방, 협력 이런 시스템과 문화가 잘 만들어져있는듯 하다. 하지만 우리나라 뿐만 아니라 아시아나 다른 지역에서는 데이터의 공유를 상당히 꺼리기 때문에 어려움이 많다고 한다.
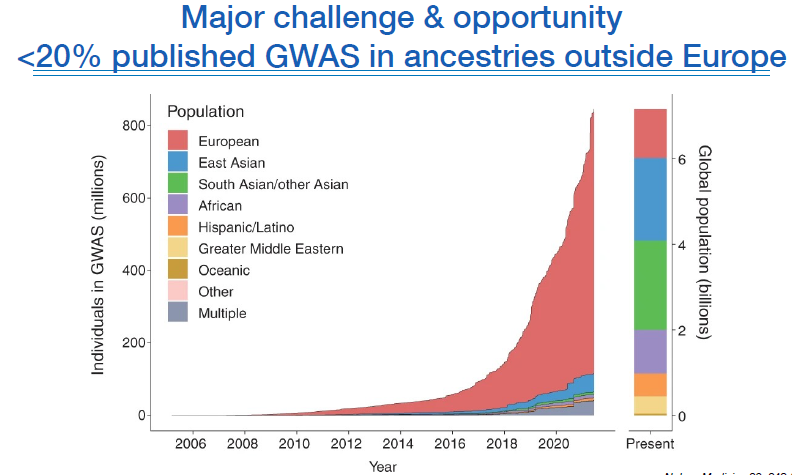
우리나라도 유전학을 선도하는 국가로 거듭나기 위해서는 단편적인 연구협력 뿐만 아니라 범기관, 국가적인 데이터 공유에 적극적으로 참여해야 할 것이다.
끝!
'medical' 카테고리의 다른 글
| [medical] 유전역학-개론 5주차, 유전체 시퀀싱 기술 (2) | 2023.04.05 |
|---|---|
| [medical] 유전역학-개론 4주차, 전장유전체 연관분석(GWAS) (2) | 2023.03.28 |
| [medical] 유전역학-개론 3주차, 연구설계방법 (0) | 2023.03.22 |
| [medical] 유전역학-개론 2주차, 기초유전학 (0) | 2023.03.21 |
| [medical] 확산강조영상(Diffusion weighted image, DWI), 확산텐서영상(Diffusion tensor image, DTI) 란? (0) | 2023.02.06 |



