
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- parer review
- deep learning #segmentation #sementic #pytorch #UNETR #transformer #UNET #3D #3D medical image
- nlp
- MRI
- non-parametric model
- genetic epidemiology
- 비모수적 모델
- 데코레이터
- nibabel
- 확산텐서영상
- 모수적 모델
- MICCAI
- Surgical video analysis
- TeCNO
- Phase recognition
- 코드오류
- 확산강조영상
- 파이썬
- parrec
- tabular
- precision #정밀도 #민감도 #sensitivity #특이도 #specifisity #F1 score #dice score #confusion matrix #recall #PR-AUC #ROC-AUC #PR curve #ROC curve #NPV #PPV
- monai
- decorater
- PYTHON
- paper review
- words encoding
- TabNet
- parametric model
- nfiti
- 유전역학
- Today
- Total
KimbgAI
[PR] TabNet(2021, AAAI) 논문 리뷰 (파헤치기) 본문
참 오랜만에 하는 논문 리뷰네요ㅎㅎ
TabNet은 Google Cloud AI팀에서 2021년 AAAI에 발표한 모델로 고성능, 고해석성을 가지고 있는 딥러닝 모델.
표 형식 데이터(tabular data)에 강점을 가지고 있는 모델임.
관련 논문은 아래 링크 참고!
https://arxiv.org/pdf/1908.07442

TabNet은 tabular data를 학습하기 위한 새로운 딥러닝 아키텍처 (오른쪽 그림)
순차적인 어텐션 구조를 바탕으로 해석력과 효율적인 학습을 가능하게 하고, 더불어 자기지도학습 방법을 적용해서 성능을 향상시킬 수 도있음.
텝넷은 Feature Transformer 블럭과 Attention Transformer 블럭으로 구성되어있고, 이러한 구조가 여러 개의 스텝을 통해 반복되는 특징을 가지고 있음.
각 스텝이 반복되는 과정에서 모델은 스스로 해당 스텝에서 사용할 변수들과 중요도를 계산할 수 있습니다.
이를 통해 텝넷은 다른 DNN 모델과 달리 높은 해석력을 제공하도록 설계되어 있음.
더불어, 텝넷은 self-supervised learning 방법을 적용해서 다양한 벤치마크 tabular 데이터셋에서 우수한 성능을 달성함.
Introduction
논문의 저자들은,
DNN은 이미지, 텍스트, 오디오와 같은 데이터에서는 좋은 성능을 보여주었지만, tabular 데이터 분야에서는 그만큼의 성능을 보여주지 못했고, 여전히 decision tree 계열의 모델들이 주로 사용되고 있다고 함.
그러한 이유로 여러가지를 들고 있는데,
첫번째로,
decision tree는 복잡한 데이터를 여러 개의 단순한 기준으로 나눠서 처리하는 데 효율적이라는 것임.
트리 모델은 데이터 공간을 반복적으로 이분법적으로 분할하여 각 노드에서 특정 feature를 특정 cutoff로 데이터를 나눔. 이 과정에서 각 분할은 매우 명확한 경계, hyperplane를 생성하며, 결과적으로 트리 모델은 계층적이고 명확한 결정 경계를 형성하게 됨.
그렇기 때문에 트리 모델은 상대적으로 간단한 구조를 가지며, 각 분할은 특정 feature의 특정 cutoff에 기반하므로 해석이 용이함.
hyperplane의 단순성과 해석 가능성은 트리 모델이 명확한 decison manifold 형성하는 데 도움이 됨.
(데이터를 나누는 기준이 되는 선을 hyperplane, 데이터가 분포해있는 공간을 decision manifold라고 함)
반면에, 딥러닝 모델은 고차원 공간에서 매우 복잡하게 학습하기 때문에 해석하기도 어렵고 쉽게 오버피팅됨.
두번째로는, (아까랑 좀 겹치는데)
decision tree는 해석 가능하다는 장점임.
decision node를 통해 어떤 식으로 결정을 내렸는지를 쉽게 이해할 수 있고, 사후 설명 가능한 방법들도 많이 개발되어 있음.
세번째로는 학습 속도가 빠르다는 점.
마지막으로,
DNN은 과도한 파라미터화와 적절한 inductive bias 의 부족으로 인해 tabular 데이터에 적합하지 않다고 함.
(inductive bias란, 머신러닝이나 딥러닝 모델이 데이터의 특징을 잘 일반화할 수 있도록 해주는 모델이 사전에 가진 가정이나 편향을 의미함. 예를 들면, CNN은 이미지의 작은 부분(패치) 단위로 특징을 추출하기 위해 설계되었고, RNN은 시간에 따라 순차적으로 입력되는 데이터의 특징을 학습할 수 있도록 만들어졌다는 것.)

그럼에도 불구하고 Tabular 데이터에 딥러닝이 필요한 이유는 다음과 같음.
첫번째로, 대규모 데이터셋에서 성능 향상이 기대되기 때문임.
딥러닝 모델은 데이터가 많을수록 더 많은 패턴과 데이터들간의 관계를 학습하기에 용이함.
두번째로, 딥러닝 모델은 이미지, 텍스트, 시계열 데이터와 같은 다양한 데이터 타입을 tabular 데이터와 함께 효율적으로 학습할 수 있다는 장점이 있음.
(즉, 멀티모달리티 기반 모델링에 아주 용이하다는 것)
세번째로는, 실시간으로 들어오는 데이터로부터 지속적으로 학습이 가능한 것.
이는 실시간 분석과 예측이 중요한 분야에서 매우 유용하게 사용될 수 있음..
마지막으로, end-to-end 모델은 representation learning이 가능함.
data-efficient domain adaptation, generative modeling, semi-supervised learning 과 같은..
(representation learning이란 모델이 데이터의 중요한 패턴과 구조를 스스로 찾아내는 것)

이 논문에서는 TabNet이라는 tabular data를 위한 새로운 딥러닝 아키텍처를 제안함.
특징으로는,
Sequential Attention 메커니즘 사용
instance wise feature selection : 데이터 개별적인 특징 선택
Interpretable decision making: 해석성
다양한 도메인의 tabular 데이터셋에서 뛰어난 성능
self supervised learning 으로 성능 향상
Method
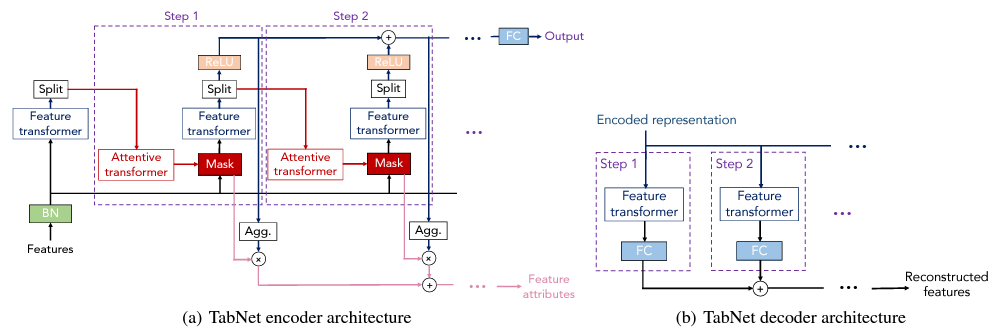
TabNet의 아키텍처에 대해 좀 더 자세하게 살펴보자면,
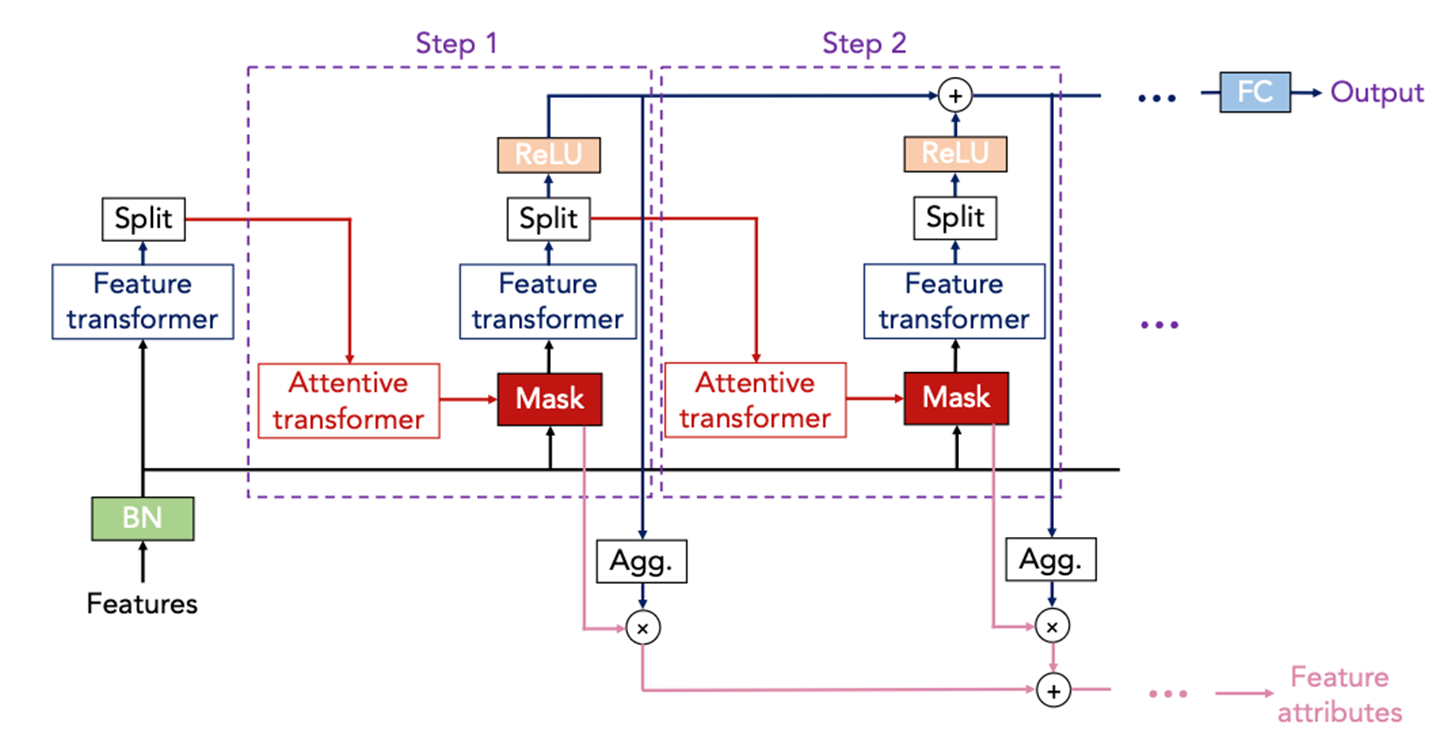
TabNet 아키텍처는 feature transformer 블럭과 attentive transformer 블럭이 여러번의 step으로 반복되며 특징을 추출하는 구조임.
하나하나 살펴보면,
입력된 데이터(Features)는 BN(Batch Normalization, 초록색 박스)을 거쳐서 Feature Transformer 블록에서 특징을 추출함.
이후 Attention Transformer 블록을 통해 mask를 생성하는데, 이 마스크는 해당 step에서 사용할 변수들의 중요도를 산출하고, 마스크는 입력과 곱해져서 해당 스텝의 feature transformer 블록으로 입력됨.
이러한 과정이 sequential 하게 반복되면서 학습이 진행됨.
한편, split 블럭에서는,
현재 스텝에서 바로 예측에 사용되는 부분과, Attentive transformer 블럭으로 전달돼서 중요한 특징을 결정하게 됨.
이 split 블럭도 역시 학습되는 영역임.
우선, 핵심인 Feature transformer 블럭과 Attentive transformer 블럭을 자세하게 살펴 보겠음.
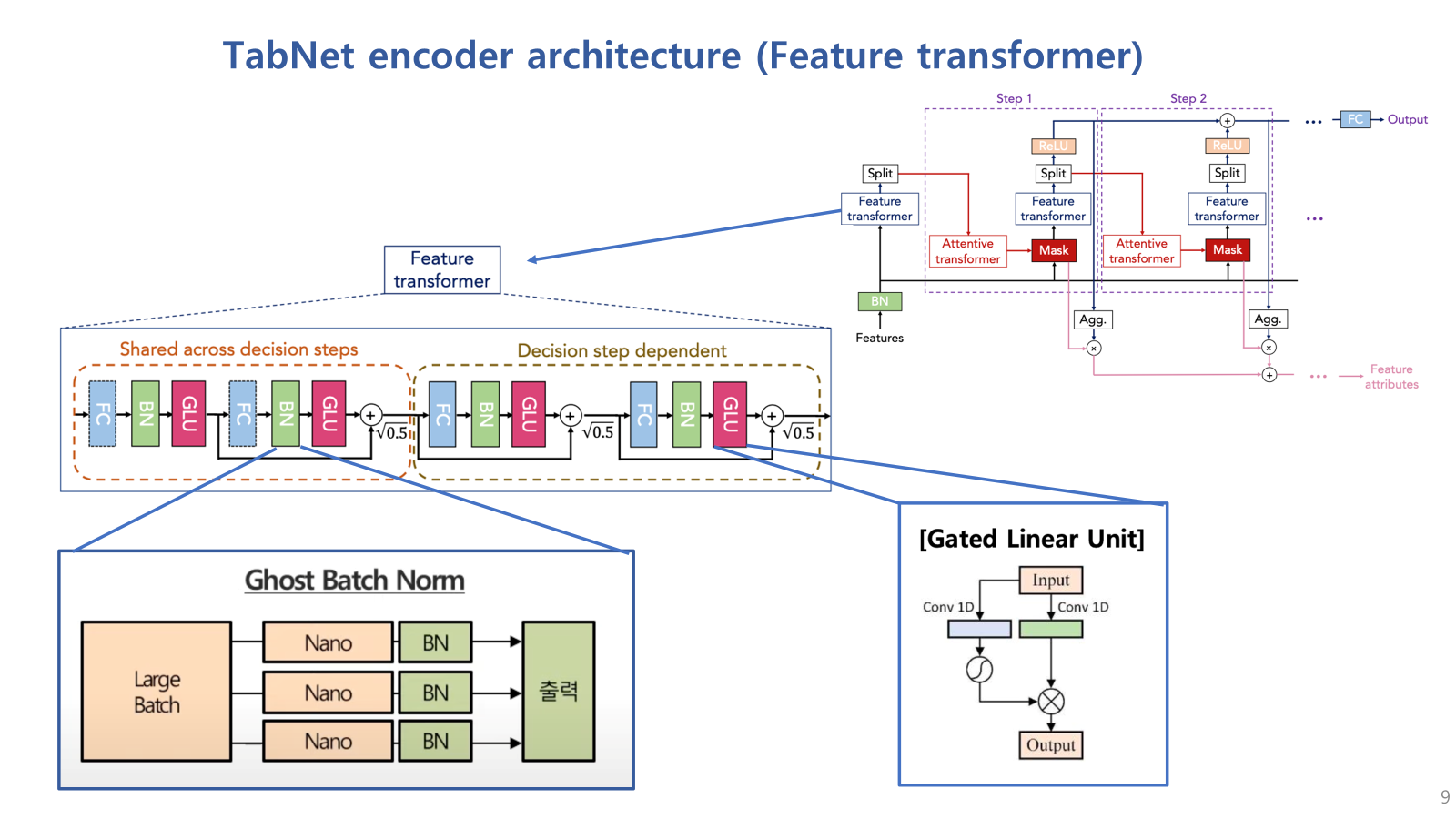
먼저, Feature Transformer 블럭은 다시 크게 두가지 section으로 나뉘는데,
shared across decision step 블럭은 모든 decision step에서 공유되는 블럭이고,
decision step dependent 블럭은 해당 decision step에만 적용되는 블록임.
그래서 Shared 블럭에서는 모든 스텝에서 파라미터를 공유하여 전체 네트워크의 global한 특징을 학습하고,
dependent 블럭에서는 각각의 스텝에서만 사용되며 local한 특징을 학습할 수 있는 블럭임.
각 섹션은 FC layer, BN, GLU(Gated Linear Unit)이 결합된 네트워크 블럭을 두개씩 가지고 있음.
여기서 사용된 BN은 ghost Batch Normalization으로,
large batch를 사용할때 흔히 발생되는 local minima 문제를 해결하기 위해 사용됨.
(GLU는 gated linear unit으로 input이 들어오면 두 개의 1d convolution branch로 나눠지고 하나는 그대로 전달되지만 다른 하나의 branch는 sigmoid 함수를 통해 확률값으로 나타내어 일종의 feature importance scoring 역할을 하고 이 feature score의 연산을 통해 최종 output을 출력함)
이제 Attentive transformer 블럭을 살펴보겠음.
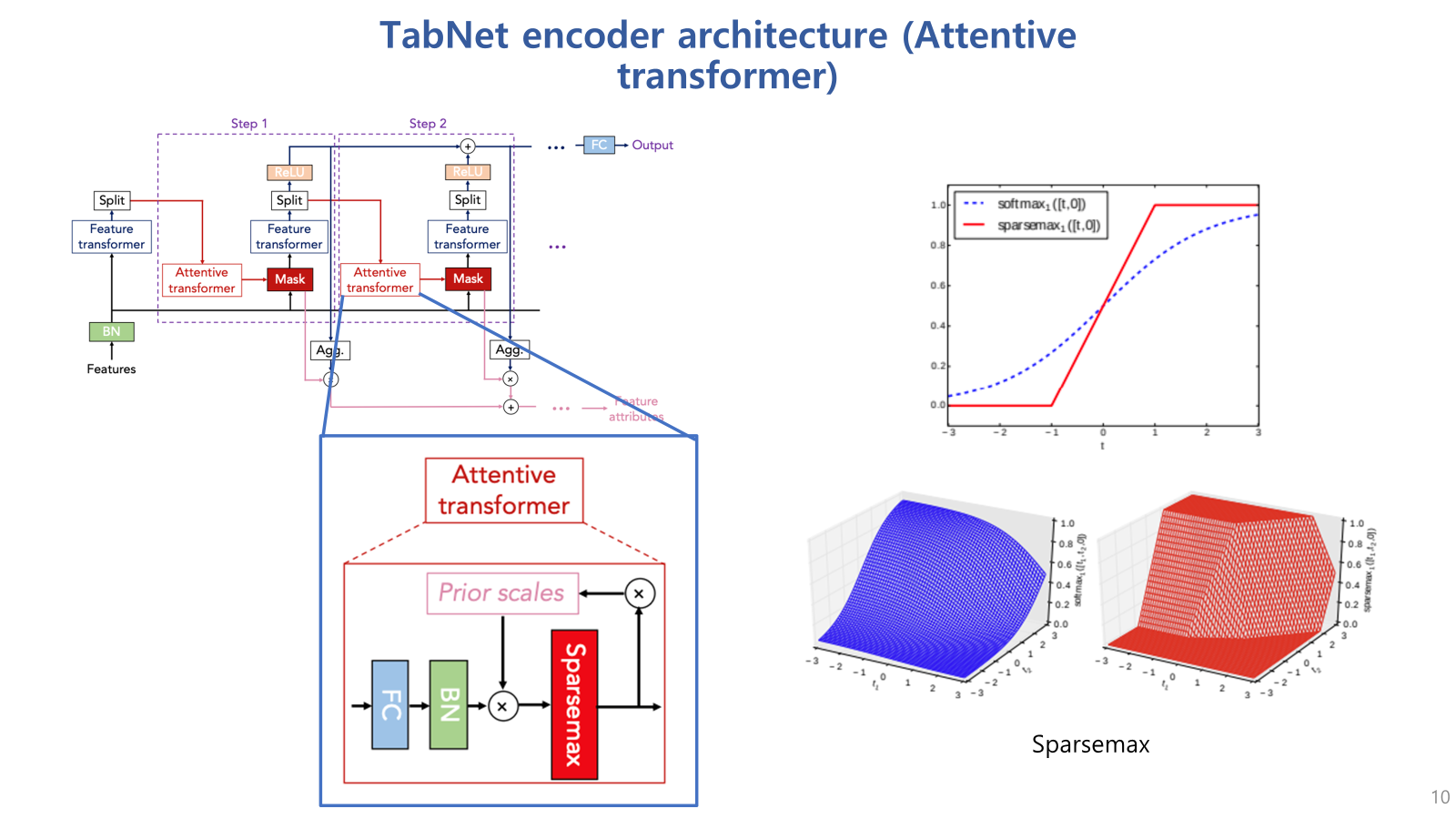
Attentive transformer는 feature의 중요도 mask를 생성하기 위한 블럭이라고 보면 되고, 비교적 간단하게 구성되어있음.
Attentive transformer 블럭은 Feature transformer의 output 중 split된 일부분을 입력으로 받고,
FC와 BN을 거친 후 prior scales라는 값을 곱해줌. (이 prior scales는 뒤에 다시 설명하겠음.)
그 후 sparsemax 거쳐서 해당 스텝에서의 마스크를 생성함.
(sparsemax는 softmax와 유사하지만, 출력값 중 일부를 0으로 만들어서, 해당 스텝에서 중요하지 않은 feature는 0으로 연산되게끔 함)
prior scales 라는 것은
특정 feature가 이전 단계에서 얼마나 사용되었는지에 대한 정보를 담고 있어서,
이전 단계에서 과도하게 중복되어 사용된 변수들을 조정하는 역할을 함.
이를 통해, 이전 단계에서 많이 사용된 특성의 중요도를 낮추어, 새로운 특성들이 선택될 수 있도록 조정함,
이는 다양한 feature를 학습할 수 있게 하며,
특정 feature에 지나치게 의존하게 하지 않도록 하게 해서 overfitting을 방지하고,
각 단계에서 새로운 특성을 학습하게 하여 학습 효율성을 향상시킴.
이는 텝넷의 sequential attention 매커니즘에서 중요한 역할을 하게 됨.
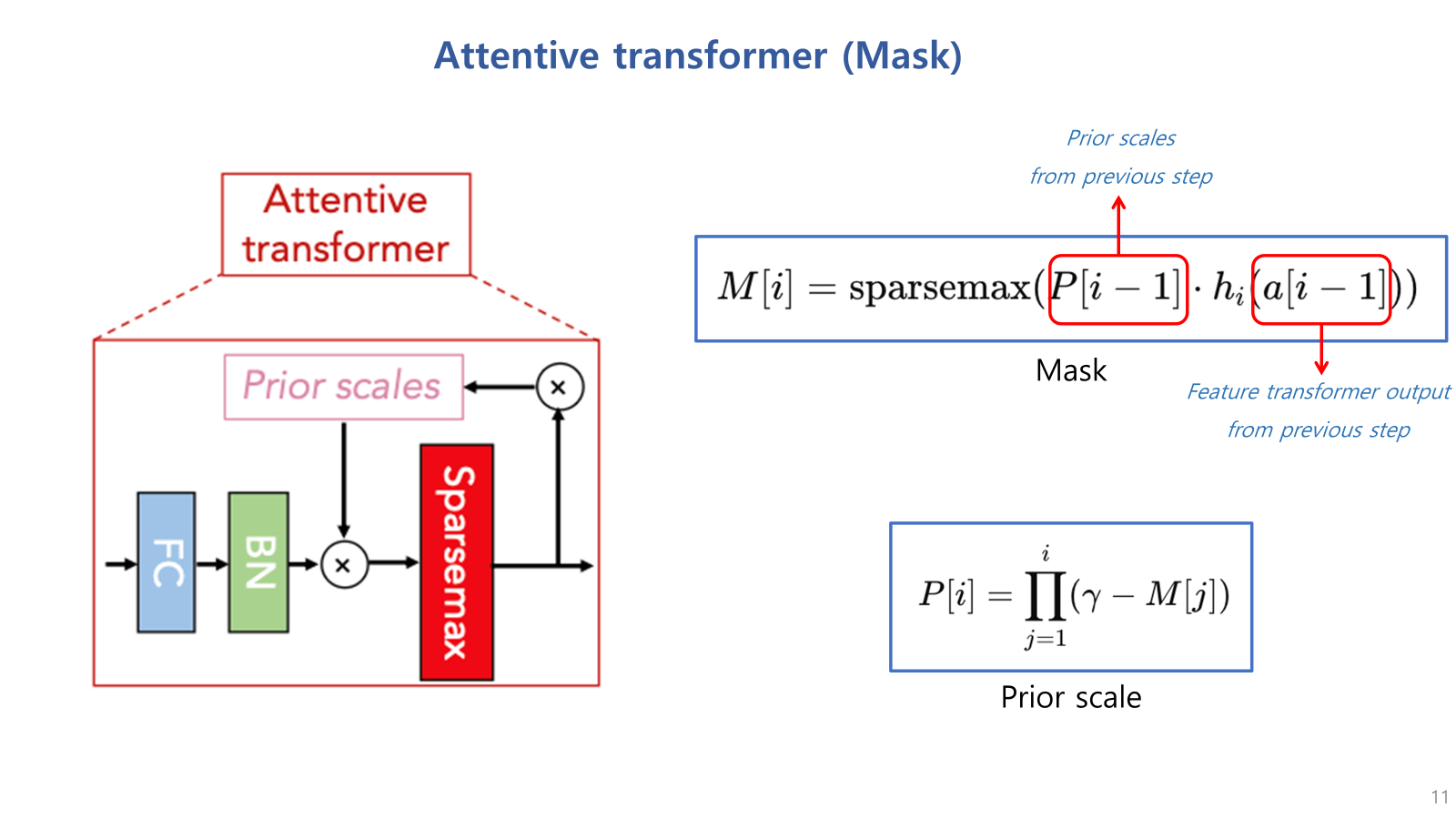
Attentive transformer를 통해 마스크가 생성되는 과정을 수식을 통해 살펴보면,
M[i] = i번째 스텝의 마스크.
첫번째 빨간 박스 p[i-1] = 직전 스텝의 prior scale.
hi는 attentive transformer의 FC & BN 레이어
a[i−1]는 직전 스텝의 feature transformer 및 split 이후의 output
즉, 현재 스텝의 마스크는 직전 스텝의 prior scale이 고려되어 생성됨.
prior scale은 현재까지 생성된 마스크들의 곱으로 계산되는데,
여기서 감마는 하이퍼파라미터로써 증가할수록 해당 변수가 여러 스텝에 결쳐 사용될 수 있음을 의미함.
즉, 감마는 여러 단계에서 특정 변수가 너무 많이 사용 되지 않도록 조절하는 역할을 함.
아래 그림은 이 sequential attention 메커니즘이 어떻게 동작하는지를 보여주는 예시인데,
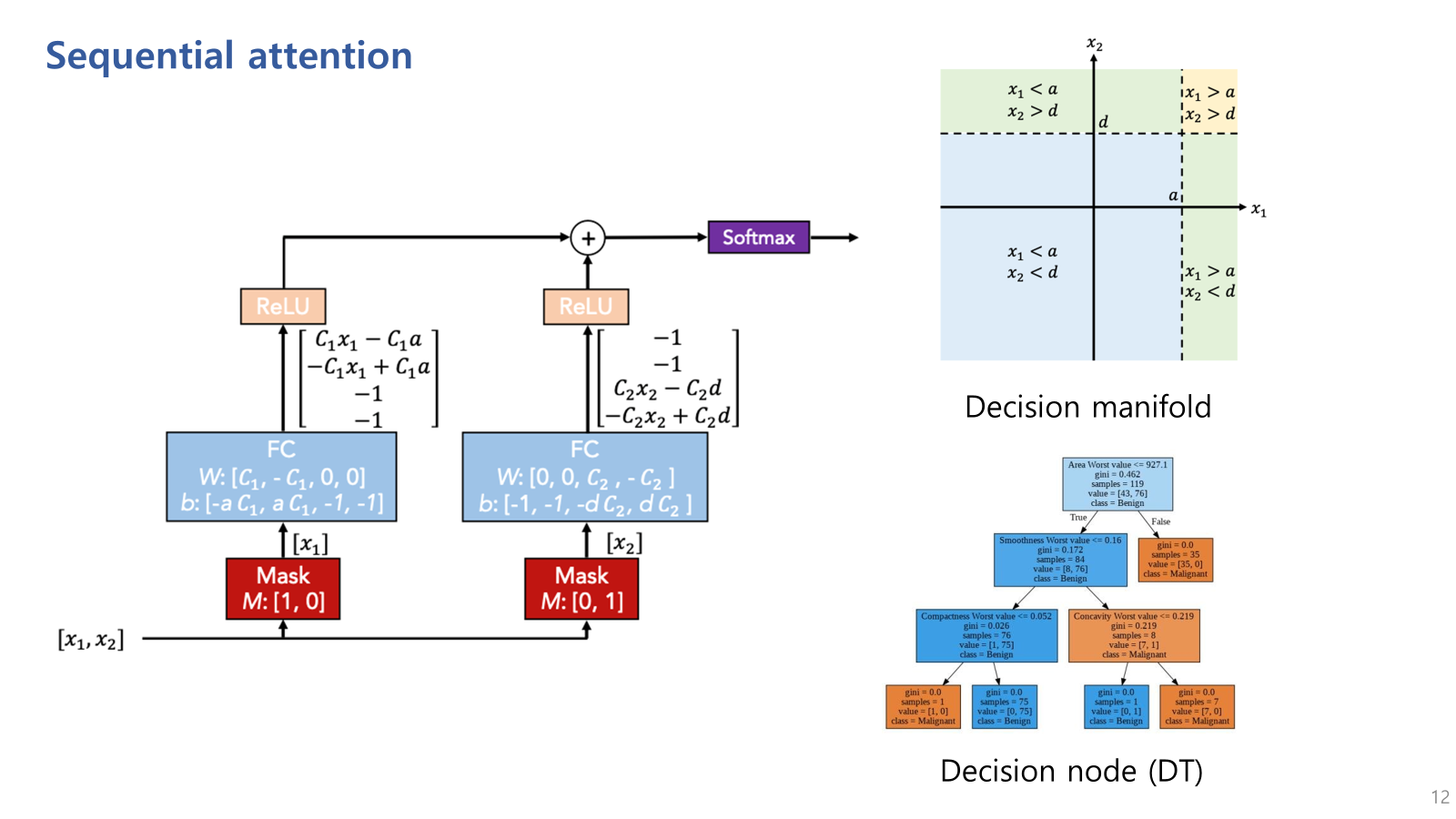
만약 빨간 박스와 같이 mask가 되어있다면,
첫번째 스텝에서는 x1 첫번째 변수만 사용하고
두번째 변수에서는 x2 두번째 변수만 사용하게 된다는 것을 의미함.
이는 step별로 중요한 feature들을 선택해 집중하는 sequential attention의 특징을 나타냄.
이러한 과정은 decision tree와 유사한 decision manifold를 형성함.
(decision manifold : 데이터를 분류하거나 예측하기 위해 특정 기준에 따라 데이터를 나누는 경계선)
우측 상단의 그림은 TabNet의 decision manifold이고,
우측 하단의 다이어그램은 Decision Tree의 decision node인데,
각 변수에 대해 독립적으로 경계를 설정하여 데이터 공간을 분할하여 decision manifold를 구성하고 있음.
죽, TabNet이 Decision Tree와 비슷한 decision boundary가 형성되는 것을 볼 수 있음.
아래 그림은 TabNet의 전체적인 학습 과정에서의 각 단계별 feature selection을 시각적으로 보여주는 예시임.
마스크가 semantic한 정보를 담을 수 있다는 것을 보여줌.
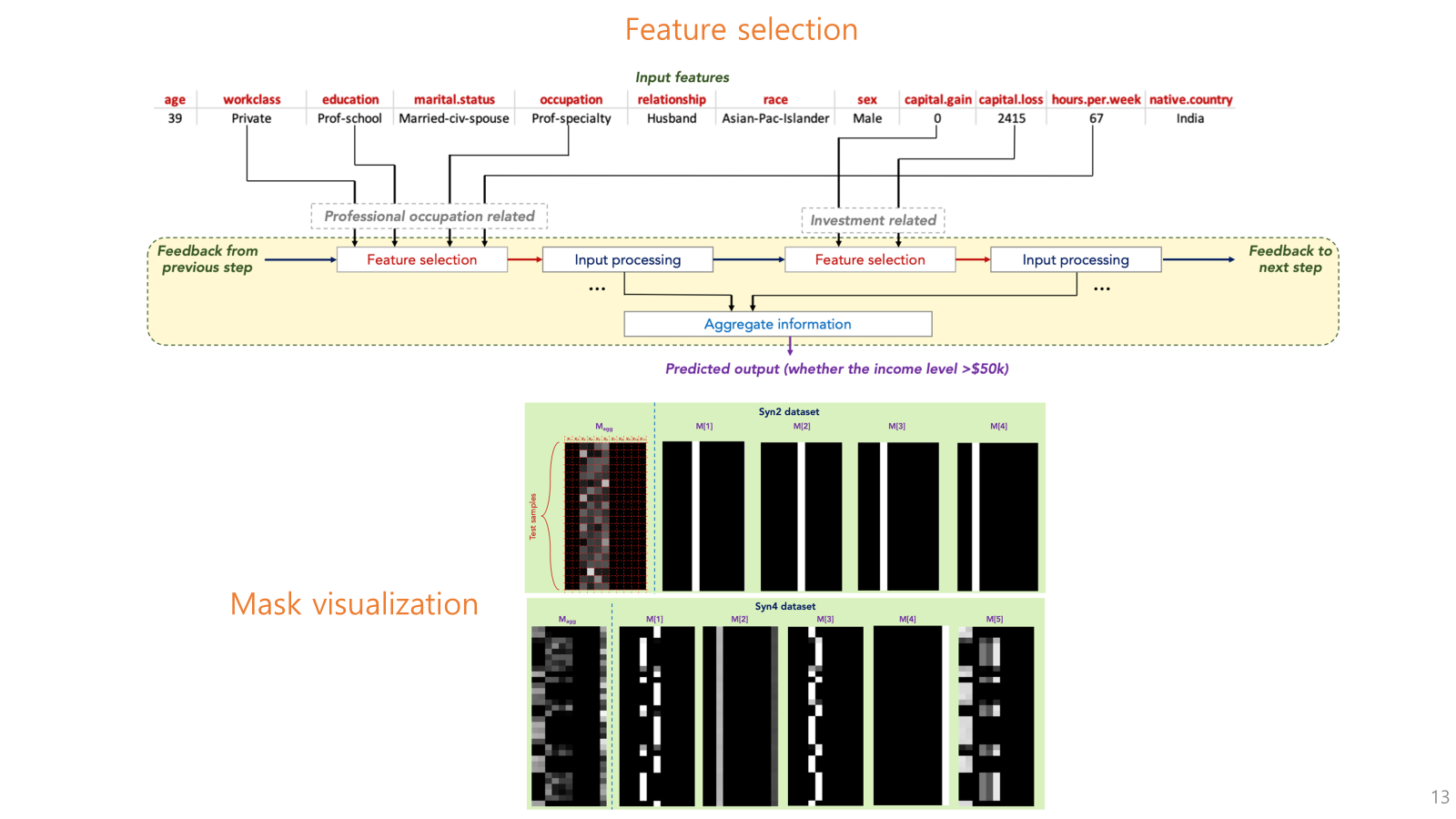
예를 들어 그림에서,
첫번째 스텝에서는 직업 관련 feature가 같이 묶여서 선택되고, (feature들간의 거리가 있더라도)
두번째 스텝에서는 투자 관련 feature가 같이 묶여서 선택됨.
그 아래에 있는 그림은 학습된 TabNet의 mask를 시각화한 것임.
세로는 각 데이터 instance를 의미하고 가로는 column을 의미하는데,
밝으면 밝을 수록 높은값 즉, 중요한 feature라는 것을 의미함.
각 마스크마다 중요한 변수들이 서로 다르게 나타나는 것을 볼 수 있고,
맨 왼쪽의 Mask aggregation은 전체 단계에서의 마스크를 합산한 결과로, 모델이 어떤 특징에 주로 집중했는지를 나타냄.
첫번째 데이터셋의 결과는 중요하지 않은 특성에 대해 거의 모두 0을 할당되어, 중요한 특성에만 집중하는 tabnet의 특징을 보여주고,
두번째 데이셋의 결과는 instance 별로 서로 다른 feature를 selection을 하는 tabnet의 특징을 확인할 수 있음.
다음은 TabNet의 또 다른 특징인 self supervised learning의 적용임.
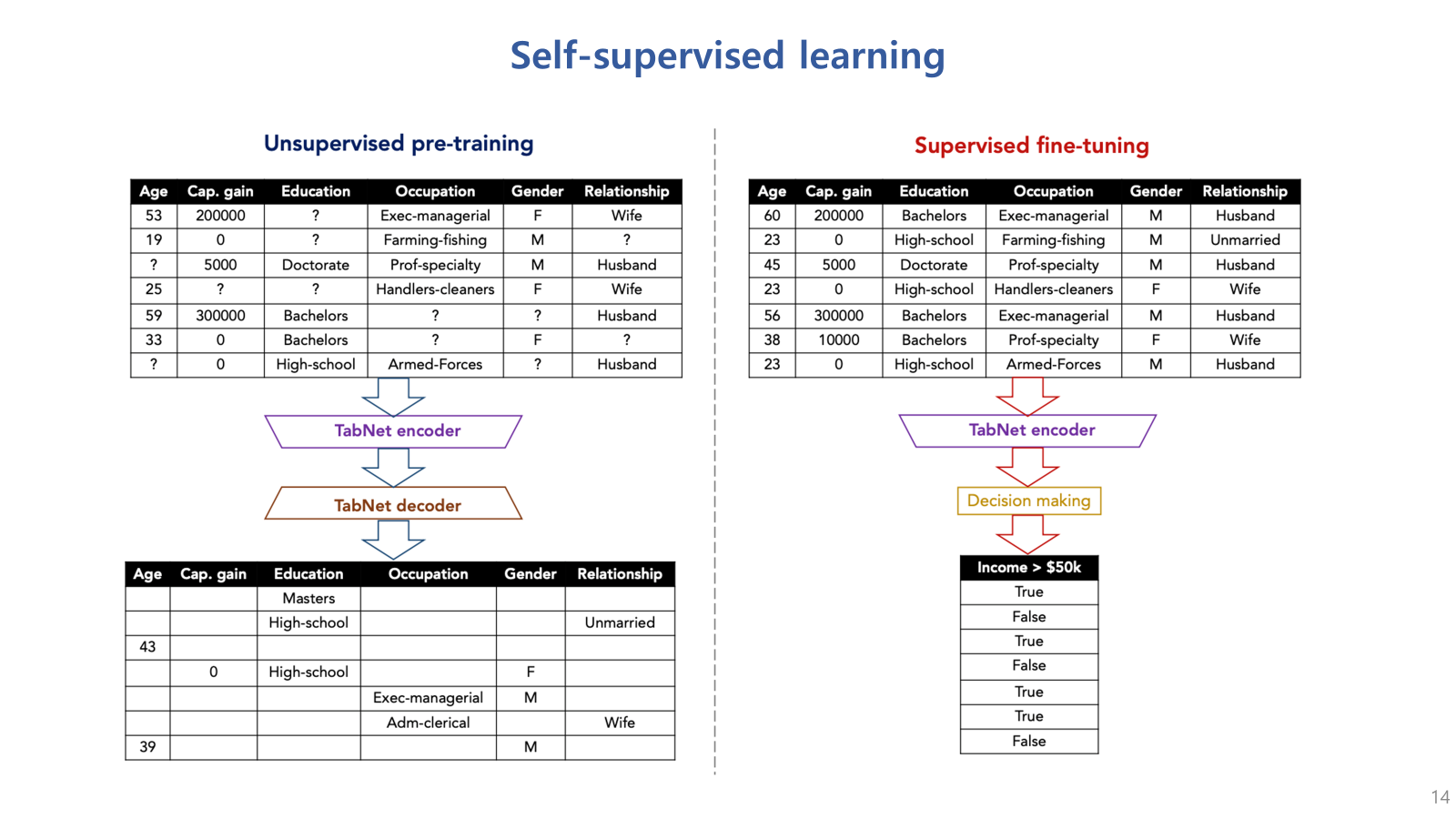
Tabnet은 self supervised learning 을 통한 성능 향상을 시도했음.
원본 데이터를 마스킹하고 이를 복원하는 masked auto encoder 기반 방법을 적용함.
인코더와 디코더 구조는 아래 그림과 같음.
이 self supervised learning은 모델의 성능을 향상시키고, tabular data 특성상 누락된 데이터가 많은데,
이러한 문제를 해결하는데 중요한 역할을 할 수 있음.
Results & Experiments
실험 결과를 보면,
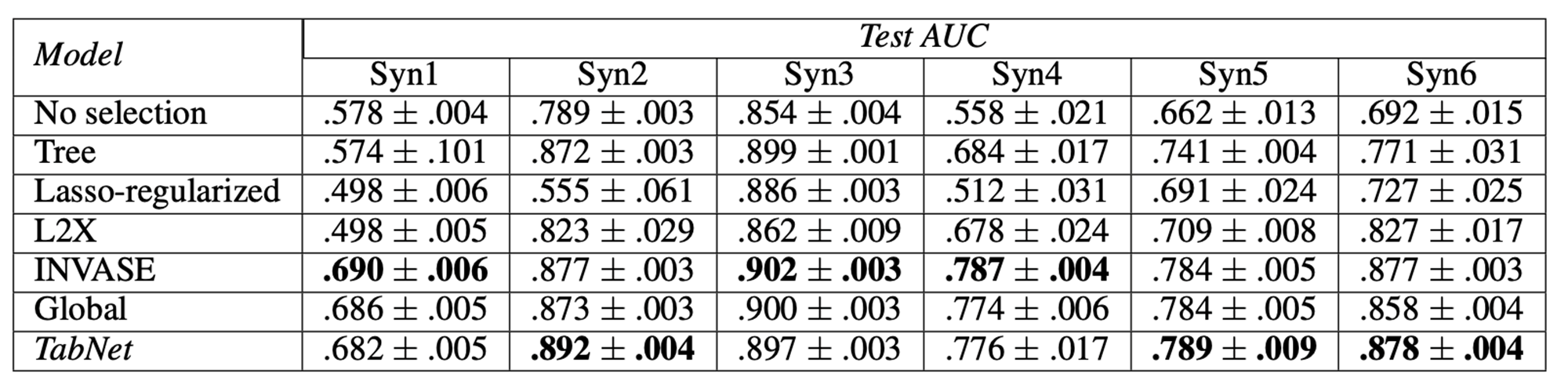
합성 데이터셋(synthetic datasets)으로 평가함.
(합성 데이터셋은 모델의 성능을 평가하기 위해 임의로 만들어진 데이터셋임.)
synthetic dataset은 각각 다른 특성을 가지도록 생성되었는데,
예를 들어 Syn1 ~ Syn3은 모든 인스턴스에서 같은 feature(column)들이 중요하도록 만들어짐.
반면, Syn4 ~ Syn6은 인스턴스별로 중요한 특징들이 다르도록 설계됨.
따라서 Syn1 ~ Syn3은 모델이 중요한 특성을 잘 포착하는지 확인하기 위한 데이터셋이고,
Syn4 ~ Syn6은 모델이 instance-wise feature selection을 잘 수행하는지 확인하기 위한 데이터셋임.
그치만 TabNet의 성능이 항상 다 높게 나오지는 않음.
(INVASE와 비슷한듯..
다만, INVASE는 3개의 네트워크가 결합된 형태로 존재하는데, 각각의 네트워크는
1) 각 샘플에서 중요한 특징을 선택하는 Selector 네트워크,
2) 선택된 특징을 활용해 최종 예측을 수행하는 prediction 네트워크,
3) 선택된 특징이 예측 성능에 얼마나 기여하는지를 계산하고 비교할 수 있도록 하는 baseline 네트워크로 구성되어 있음.)
다음은 real world dataset에 대한 실험결과.
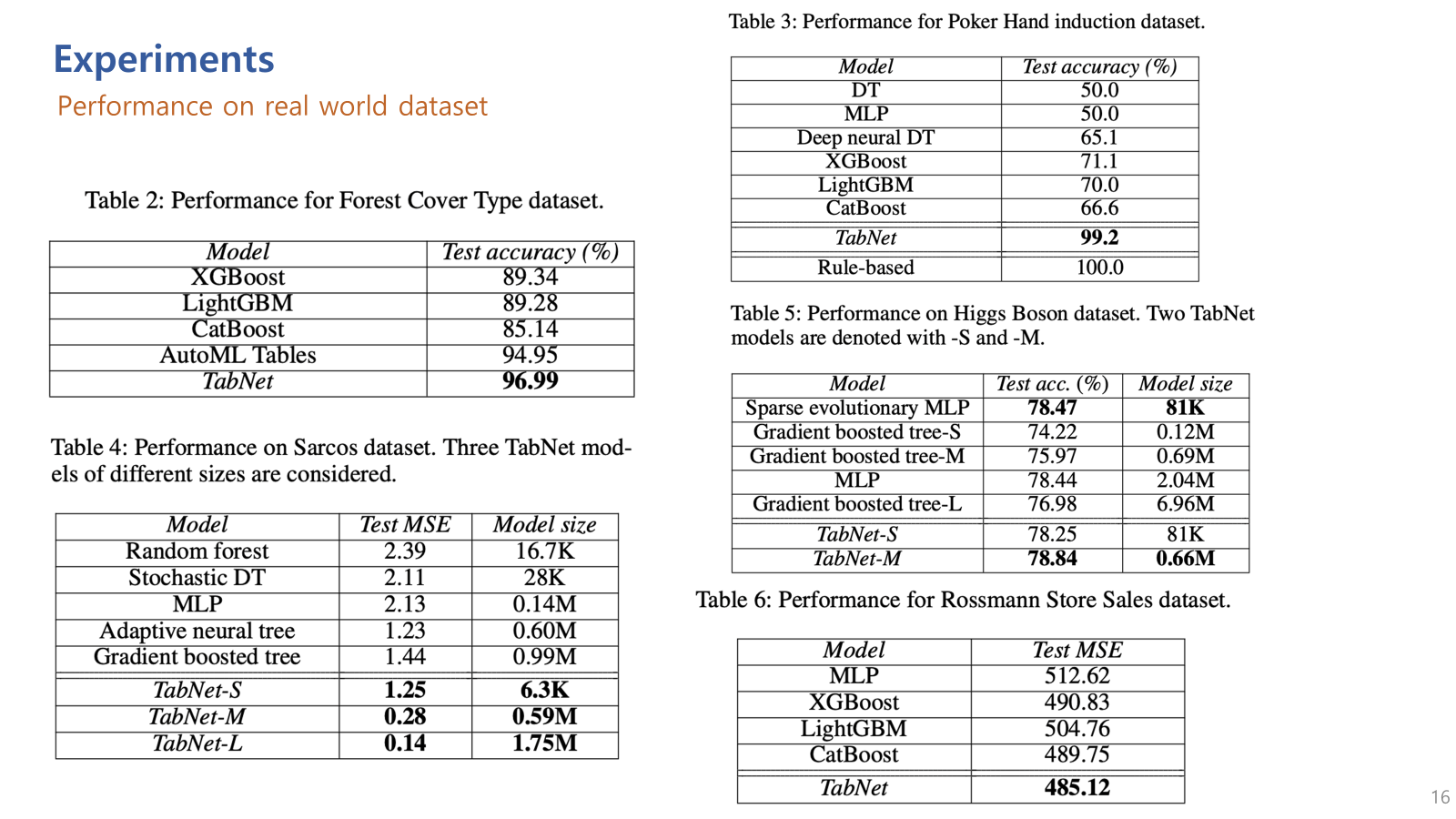
Table 2(multi-class)에서 사용된 데이터셋은 미국 콜로라도주의 루즈벨트 숲에서 수집된 데이터로, 토양, 고도, 경사도 등 다양한 환경적 특성을 기반으로 각 지역의 나무 종류를 분류하는 문제임.
결과: TabNet은 96.99%의 테스트 정확도를 기록하며, 다른 모델들보다 높은 성능을 보여줌
Table 3(multi-class)에서 사용된 데이터셋은 포커 핸드 게임의 카드 조합을 기반으로 각 핸드의 가치를 분류하는 문제임.
결과: TabNet은 99.2%의 테스트 정확도를 기록하며, 다른 모델들보다 월등히 높은 성능을 보여줌
Table 4(Regression)에서 사용된 데이터셋은 Sarcos 로봇팔의 관절 움직임을 예측하는 문제로, 로봇팔의 관절 위치, 속도, 가속도를 기반으로 각 관절의 힘을 예측해야함.
결과: TabNet-L은 0.14의 테스트 MSE로 가장 낮은 오류율을 보여주고 있음
Table 5 (binary)에서 사용된 데이터셋은 입자 물리학 실험에서 힉스 입자를 검출하는 문제로, 입자의 특성(에너지, 운동량 등)을 기반으로 입자의 존재 여부를 예측해야함.
결과: TabNet-M은 78.84%의 테스트 정확도로 가장 높은 성능.
Table 6 (Regression)에서 사용된 데이터셋은 로즈만이라는 독일 소매업체의 매출 데이터를 기반으로, 매장의 일별 매출을 예측하는 문제.
결과: TabNet은 485.12의 테스트 MSE로 가장 낮은 오류율을 보임.
다양한 real-world dataset에서 우수한 성능을 보여줌
(근데 왜 아까 합성데이터셋 평가에서 사용한 INVASE와 같은 모델은 사용하지 않았는지는 의문..)
마지막으로 self supervised learning을 적용 여부에 따른 성능 차이.
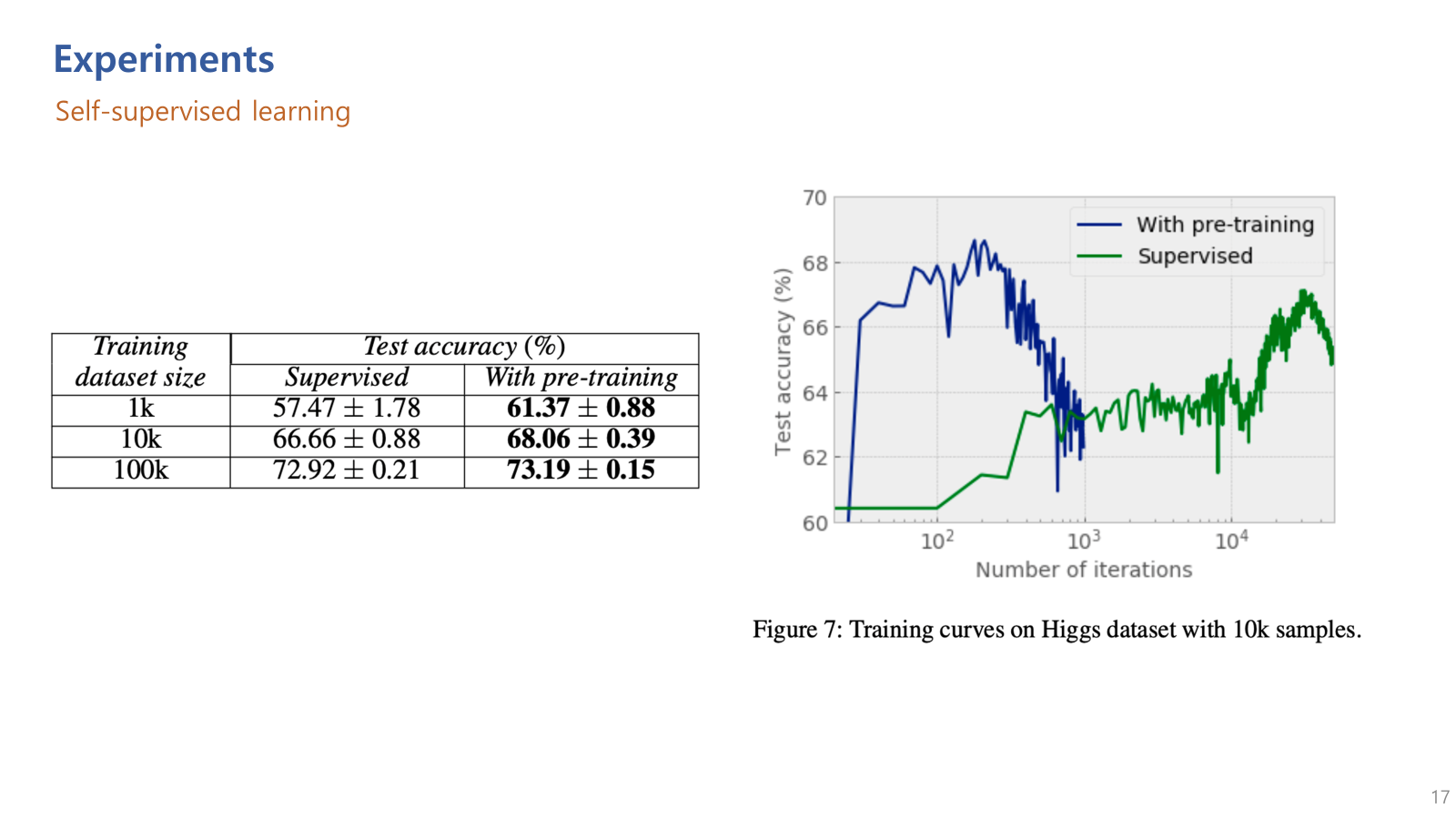
Self-supervised learing을 적용했을때, 당연하겠지만 학습 속도도 빠르고 성능도 향상됨을 볼 수 있음.
끝!!
'machine learning' 카테고리의 다른 글
| [오류해결] monai metrics 중 DiceMetric의 y, y_pred 인식 오류 (0) | 2024.03.27 |
|---|---|
| 이미지 내 색상 별 픽셀 수 확인하기 (0) | 2023.03.09 |
| [ML] 분류 평가 지표 정리(sensitivity, recall, precision, specificity, f1 score, NPV, PPV (0) | 2022.11.22 |
| [ML][pytorch] UNETR(21.03); UNEt TRansformers 코드 설명 및 구현 (2) | 2022.11.21 |
| [ML] Data augmentation for 3D medical image (3) | 2022.11.17 |



