
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 확산강조영상
- precision #정밀도 #민감도 #sensitivity #특이도 #specifisity #F1 score #dice score #confusion matrix #recall #PR-AUC #ROC-AUC #PR curve #ROC curve #NPV #PPV
- Phase recognition
- non-parametric model
- MRI
- paper review
- 유전역학
- PYTHON
- parrec
- Surgical video analysis
- 비모수적 모델
- genetic epidemiology
- 파이썬
- nlp
- 데코레이터
- deep learning #segmentation #sementic #pytorch #UNETR #transformer #UNET #3D #3D medical image
- MICCAI
- parer review
- 모수적 모델
- nfiti
- words encoding
- nibabel
- TabNet
- 코드오류
- monai
- decorater
- 확산텐서영상
- parametric model
- tabular
- TeCNO
- Today
- Total
목록nlp (2)
KimbgAI
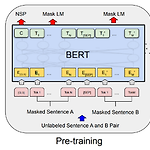 [NLP] BERT에 대한 간단 설명 (paper review)
[NLP] BERT에 대한 간단 설명 (paper review)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018). 2018년에 구글에서 발표된 너무나도 유명하고 NLP 공부할때 milestone이 되는 모델이다. 시작해보자. 개요 언어모델을 개발할때 양질의 pre-trained word representation을 사용하는 것은 매우 중요함. 왜? 좋은 word representation은 down-stream tas..
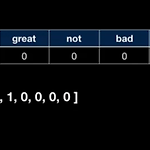 [NLP] 다양한 word encoding 방법 (bag of words, N-gram, TF-IDF)
[NLP] 다양한 word encoding 방법 (bag of words, N-gram, TF-IDF)
이 내용은 유투브 허민석님의 자료를 공부하며 정리하기 위해 작성된 내용임을 밝힙니다. https://www.youtube.com/@TheEasyoung bag of words 란? 단어는 머신러닝 모델에 입력으로 사용하기 위해 숫자로 변환되어야함. 이를 위한 다양한 방법들이 있는데, 그 중 가장 기초적인 것이 바로 bag of words 라는 것으로 굉장히 심플하다. 전체 데이터셋에서 나타나는 모든 단어 기반으로 임의의 문장을 원핫인코딩(one-hot encoding)하여 나타낸 것. 가령, 아래와 같이 나타내는 것이다. 전체 데이터셋에서 나타나는 각각의 유니크한 문자들을 나열하고, 어떤 문장을 이루는 단어들이 해당 문장에 몇번 나타났는지 표기하는 것이다. 이로써 다른 문장들과의 유사성도 계산할 수 있다..