
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 확산강조영상
- deep learning #segmentation #sementic #pytorch #UNETR #transformer #UNET #3D #3D medical image
- nfiti
- parametric model
- parrec
- 코드오류
- 데코레이터
- precision #정밀도 #민감도 #sensitivity #특이도 #specifisity #F1 score #dice score #confusion matrix #recall #PR-AUC #ROC-AUC #PR curve #ROC curve #NPV #PPV
- 유전역학
- 비모수적 모델
- TeCNO
- nlp
- paper review
- genetic epidemiology
- parer review
- MICCAI
- non-parametric model
- Phase recognition
- 확산텐서영상
- words encoding
- 모수적 모델
- tabular
- Surgical video analysis
- nibabel
- decorater
- 파이썬
- PYTHON
- MRI
- TabNet
- monai
- Today
- Total
KimbgAI
[medical] 유전역학-개론 7주차, 유전자 변이에 대한 명명법 본문
유전자 변이 명명법을 영어로 하면 variants nomenclature이다.
유전자 연구의 목적은 이 변이를 찾는 것인데, 이 변이에 대한 명명법이 논문마다 제각각이었기 때문에 이를 표준화할 필요가 있었다. 같은 변이인데 다른 이름으로 불러 다른 것인줄 알았다던지..

위 그림은 성경에 나오는 바벨탑 그림이다.
인간이 신에게 가깝게 가기 위하여 탑을 쌓는데, 신이 노하여 함께 일하는 사람들의 언어를 다르게 만들었다는 이야기가 있다. 이처럼 부르는 언어가 다르면 바벨탑이라는 유전자 공동 연구에 한계가 있는 것과 같은 맥락이다.

특히나 의료현장에 사용되는 언어는 '생명의 비가역성'이라는 개념 때문에 더 중요하다.
어떤 변이로 인해 어떤 테라피를 진행했는데, 그게 잘못되어 생명에 지장을 줄 수 있다면 그건 되돌수가 없기 때문이다.
유난히 이 변이에 대한 표현법이 여러가지이다. 가장 큰 이유는 교육의 부재이다.
누구 하나 태클 거는 사람이 없고, 논문에 나왔으니 그저 그대로 사용하고..
예전에는 이런 변이에 대해 보고할 케이스가 적었고, 연구 목적 외에 사용이 적었지만, 현재는 환자뿐만 아니라 건강한 사람들도 DNA 칩을 통해 유전자 검사를 하여 변이를 보고받는 시점이 되었다.
그렇기 때문에 잘못보고가 되면 문제가 생기기 때문에 더욱 중요해졌다.
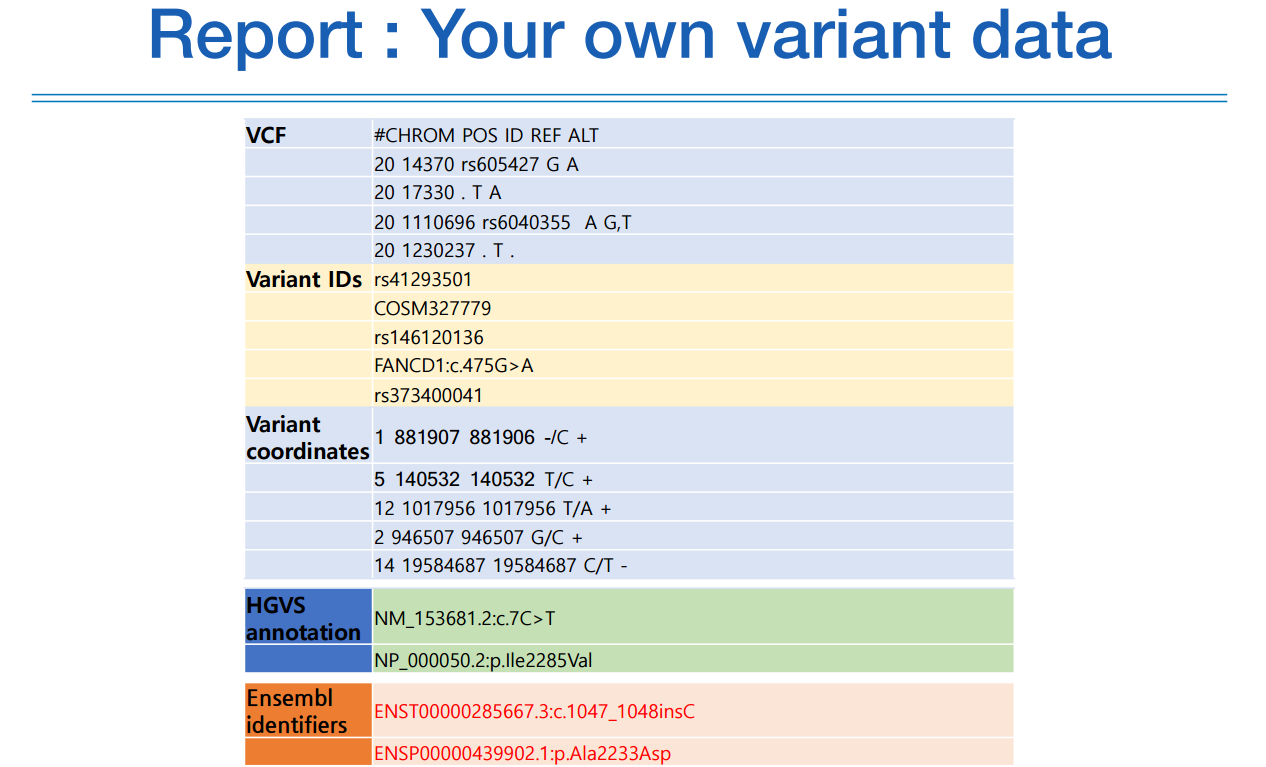
이처럼 다양한 방식으로 변이를 부른다. 지금은 뭐가 뭔지 모르겠지만,
이 내용이 끝날때 쯤이면 위 내용이 무슨 말인지 대강 이해할 수 있을 것이다.

일반적으로 표준화의 조건은 위와 같다.

유전자 변이 명명에 앞서서, 정확한 유전자 이름이 무엇인지 알아야한다.
환자에게 보고가 되는 변이들은 대부분 nonsynonymous, 즉 유전자 위에 있는 변이, 엑손 위에 있는 변이 중에서도 실제로 protein, 아미노산이 바뀌는 변이가 pathogenic하여 환자에게 영향을 끼치고 causal variant기 때문이다.
유전자가 새로 발견이 되면, 밝견한 연구자가 그 유전자의 이름과 심볼을 붙히는데 이를 HGNC라는 곳에서 유전자 symbol과 이름을 승인하여 관리한다.

gene symbol은 해당 유전자를 간단하게 약어로 표기하는 것이다.
gene symbol 자체에 대한 명명법은 단백질 이름을 쓰거나, mutant의 이름을 쓰거나 등등 자유로우나, 몇가지 규칙이 있다.
human gene 같은 경우는 전체 대문자를 사용해야하고, 이탤릭체로(눕혀서) 표기해야 한다.
로마숫자나 그리스 알파벳, 몇가지 구두점은 사용할 수 없다.

gene name은 gene symbol을 풀어쓴 풀네임이라고 보면 된다.
위의 내용처럼, gene name의 첫 글자는 심볼과 같게 시작해야하고 동시표기할때는 " "를 사용하여 표기한다.

추가적으로 몇가지 약속들이 있는데,
L이 붙는것은 like라고 해서 해당 유전자와 염기서열상 아주 유사한데, 조금 다른 것을 의미한다.
P가 붙는것은 pseudogene이라고 해서, 해당 유전자랑 완전 똑같이 생겼지만 function은 하지 않는 것이다.
아래는 유전자로 추정은 되지만 아직 밝혀지지 않은 것들을 의미한다.
풀네임을 봐도 해당 포지션에 대한 내용만 있을 뿐이다.

심볼과 이름을 같이 보면 위와 같이 쓸 수 있다.

앞서말한 HGNC 사이트에 해당 변이를 검색하게 되면 사용해야하는 공식 심볼과 이름을 확인할 수 있다.
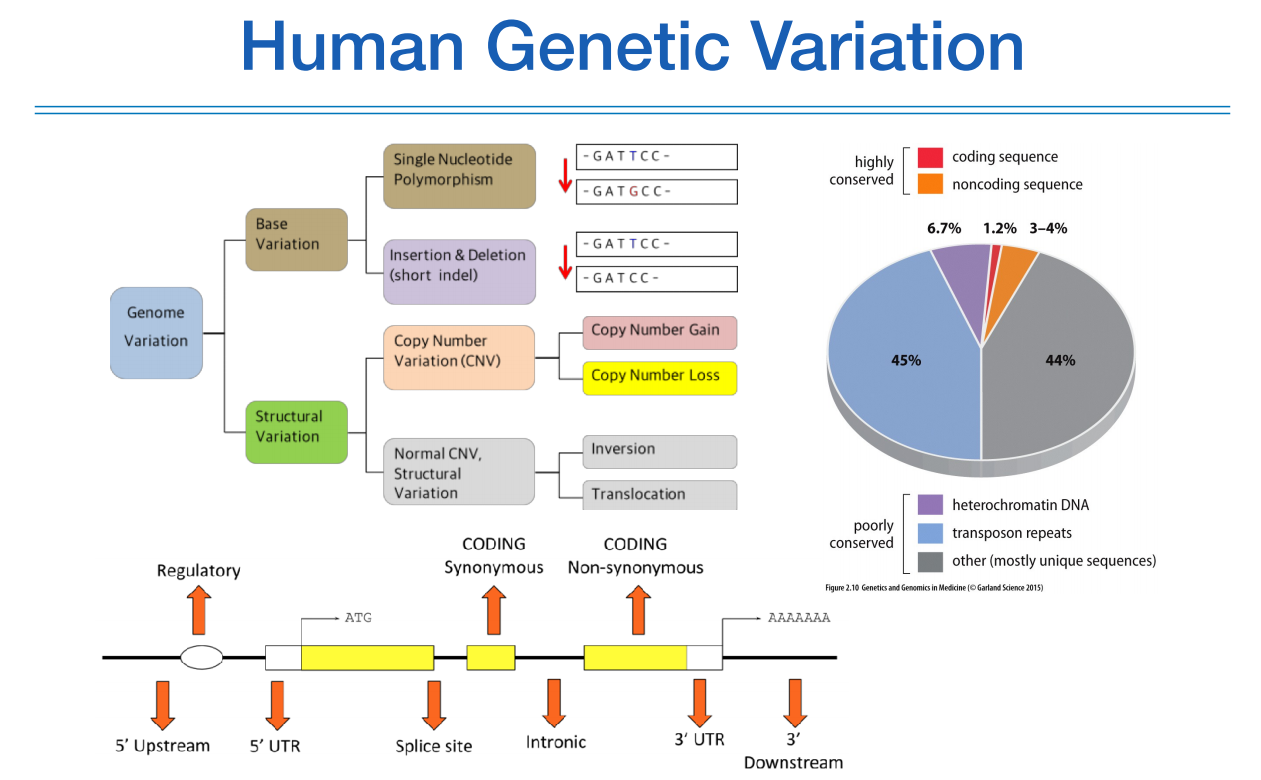
휴먼 지놈 30억 전체에 대해서 변이가 발생하지만, 실제 코딩시퀀스 부위, 단백질을 만드는 부분은 얼마 되지 않고, 이 부분에 대해서 이야기를 할 것이다.
따라서 실제로 만드는 부분은 위 그림에서 노란색과 같은 엑손 부위이지만, 5`, 3` UTR까지 포함한다.
노란색(엑손) 사이의 인트론 부분은 실제로 단백질을 만들진 않지만, 잘 잘려나가는 것 또한 중요하기 때문에 인트론 변이도 중요하다.

변이 자체는 똑같은데 다른 ID를 가지고 있을 수 있다는 것에 유의해야한다.
데이터를 공개하는 DB에 따라 다르게 표현된다.
SNP이나 INDEL과 같은 짧은 변이들은 왼쪽에서 관리한다. 1kb이상되는 구조적 변이는 오른쪽에서 관리한다.
왼쪽부터보자면, ss와 rs라는 id는 NCBI에서 관리한다. rs는 reference snp을 의미한다.
ss같은 경우는 검증이 되면 rs로 넘어올수도있는데, polymorphic한지 아직 모르는 경우에는 ss에 속한다.
HGVS는 HGNC에서 관리하고 있는 DB이고, 이 시간에 배울 명명법은 이 방식으로 표현된 variant를 배울 것이다.
이 표현법은 실제 변이의 정보를 다 보여주고 있는 명명법이다.
COSMIC은 cancer와 같은 somatic mutation관련 된 것이다.
ClinVar도 NCBI에서 관리하는 것인데, 변이들 중에 클리닉하게 의미있는 것들만 모아놓은 것이다.
오른쪽에서 기억할 것은 구조적 변이는 모두 sv로 표현된다는 것만 알면 된다.

각각의 DB에서 부르는 이름은 다를지언정 하나로 통일된 명명법이 있는데, 이것이 바로 HGVS에서 관리하고 있는지 포멧이다.
표현법은 가장 먼저 레퍼런스 시퀀스를 쓰고, 콜론 뒤에 variant 정보를 쓴다.
그럼 먼저 레퍼런스를 어떻게 써야하는지 알아야한다.

NCBI 표현법 먼저 보면,
NC는 complete genome이고, NG는 완성되지 않은 gonome 영역이다.
NM는 mRNA 영역이고 즉 코딩영역이다.
NR은 non-coding RNA이고, NP는 protein이다.
Ensembl 표현법은, ENS로 시작하여,
ENSG는 NC랑 같고, ENST는 NM과 같고, ENSP는 NP와 같고 그렇다.
다른 종에 대한 표현은 ENS뒤에 뭐가 더 붙는다 정도만 알면 된다.
NC_000001은 1번 염색체이고 NC_000022는 22번 염색체이다.
NC_000023은 x염색체, NC_000024는 y염색체이다.
NC_000019 뒤에 .10은 패치정보이다.
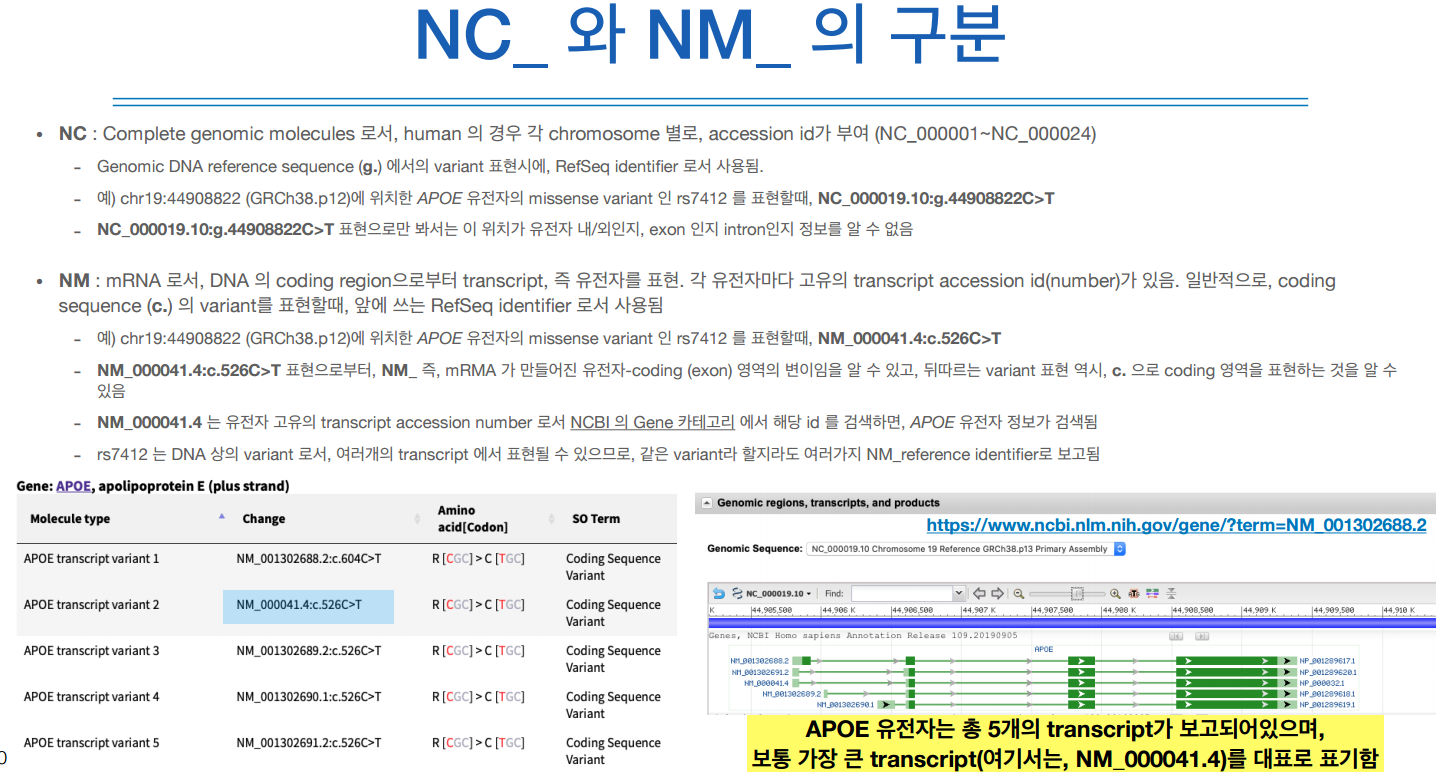
NM은 mRNA이고 NC보다 구체적인 정보를 담고 있다. 즉 NM은 NC의 하위집합이며, NM은 NC로도 표현될 수 있다.
NM뒤에는 염색체 번호를 의미하는것이 아니다.
NCBI에서 APOE라는 유전자 심볼을 검색하면 위와 같은 정보가 나온다.
APOE는 transcript를 5개를 만들고(초록색), 그 중 대표 transcript는 가장 긴 것을 의미한다.

콜론 뒤에는 변이에 대한 내용이 있고, g,m,c,n 등 다양한 알파벳이 올 수 있다.
g는 30억 염기서열 전체 상에서 이야기하는 것이고,
m은 미토콘드리아 관련 내용, c는 코딩영역이고, n은 non-coding영역, r은 RNA, p는 protein이다.

DNA 표현법은 g 또는 c 이다.
g.123A>T 는 123bp가 A에서 T로 바뀌었다 하는 이야기이다. (그 위치가 유전자 인지 아닌지는 모름)
RNA 표현법은 비슷한데 소문자를 사용해야한다.
조심해야할 것은 RNA를 시퀀싱하지 않고 DNA만 시퀀싱했는데, DNA가 바뀌었으니까 RNA가 바뀌었을 것이라고 추측만으로 r.123a>u 와 같이 쓰면 안되고, r.(?)으로 작성해야한다. (rna는 시퀀싱 안해서 모르겠습니다 라는 표현)
마찬가지로 protein 레벨에서도 g.123A>T으로 인해 Histidine이 Glutamin으로 바뀌는데, 이것 역시 괄호 안에 넣어 표시해야한다. (p.(His78Gln))
한편, 아미노산의 조합은 3개의 염기서열(codon)이 아미노산 1개를 만드는데, 3개의 염기서열로 나오는 아미노산의 조합의 수는 4x4x4으로 64가지가 아니라 22가지이다.
왜냐하면 염기서열이 다르더라도 같은 단백질을 만들어내는 경우가 있기 때문이다. (TTT == TTC -> synonymous variant)
회색은 stop codon으로 아미노산을 만들지 않는 경우인데 이는 *으로 표기한다.

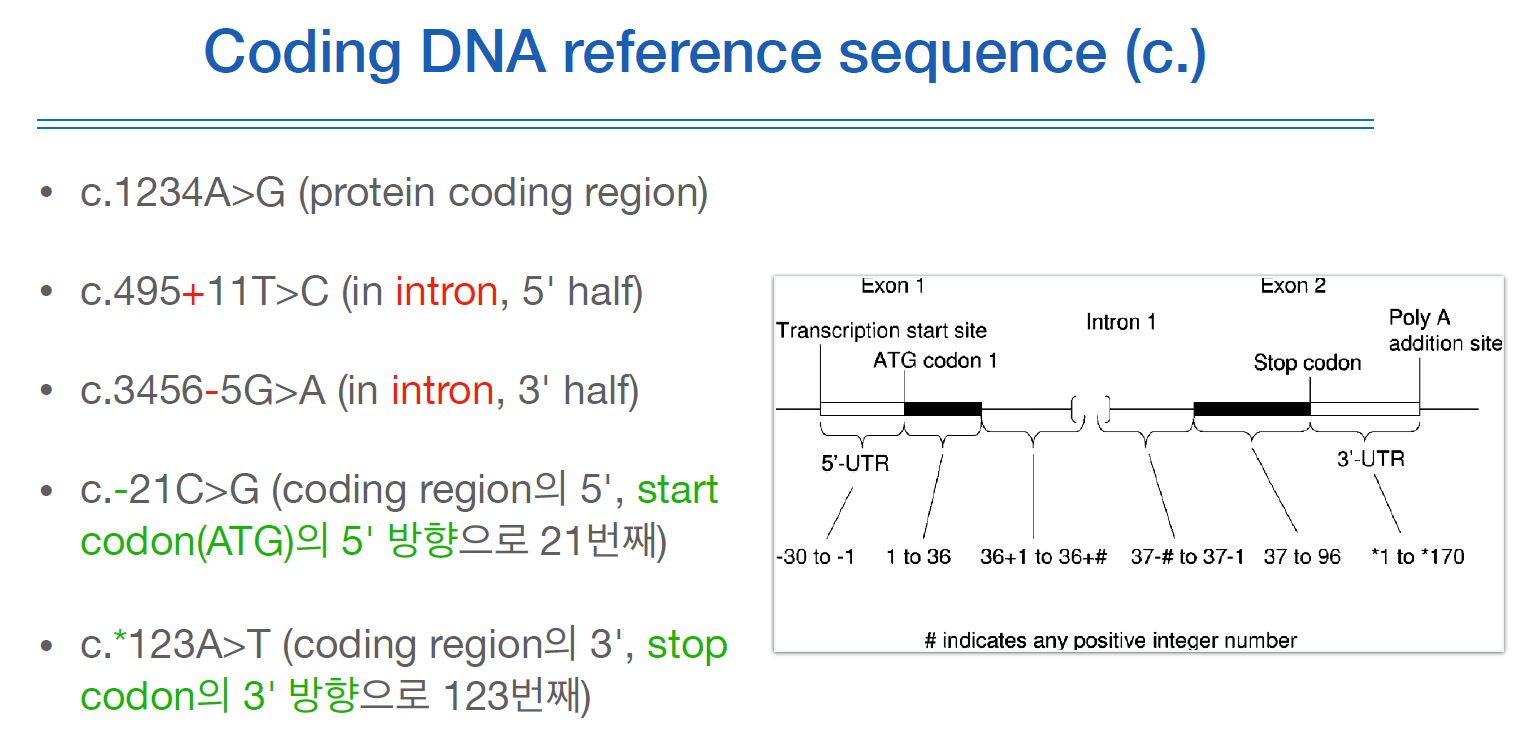
언제 g.를 쓰고 언제 c.를 쓰냐 하면, c.로 표현되는 것은 모두 g.로 표현될수 있다.
하지만 g.로 표현되는 것이 모두 c.로 표현할 수 있는 것은 아니다. 유전자 영역언 2%정도밖에 되지 않기 때문에.
g.는 말그대로 어떤 염색체의 몇번째의 bp인지는 나타내준다.
NC_000001.12:g.12341234라면 첫번째 염색체의 12341234번째의 bp라는것이다.
c.는 포지션을 나타내는 것은 아니고,
c.2396-6G>A는 2396번째의 코딩영역(코돈)에서 (-) 이기때문에 왼쪽으로 6칸 움직인 위치(즉, 인트론) 이다.

이런 느낌..?
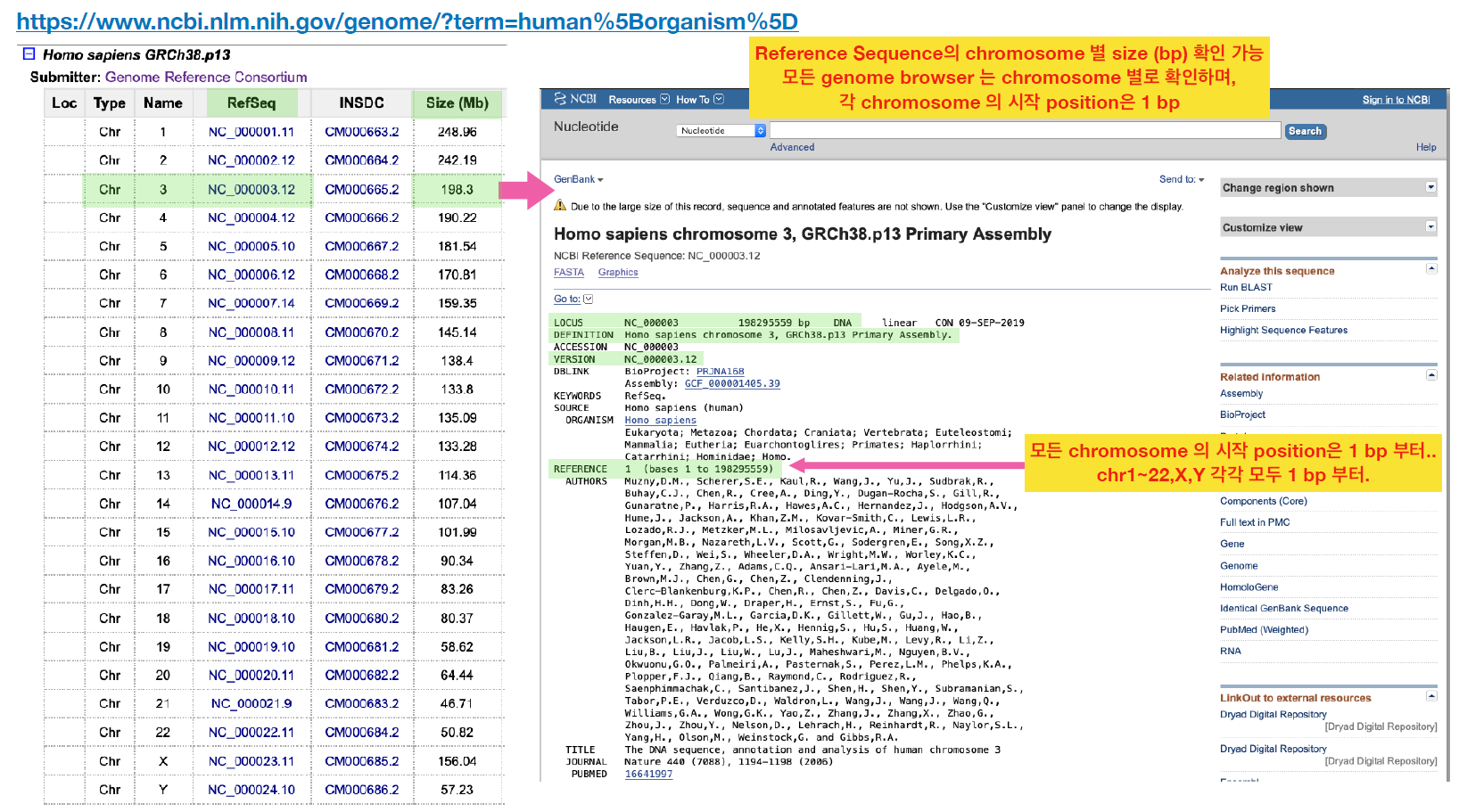
NCBI 홈페이지 가서 확인을 해보면 NC에 관련된 정보를 찾을 수 있고, 보통 뒤에있는 염색체일수록 짧은 길이를 가지는 걸 또 볼수있다.

보면 알겠지만, 보통 NC 짝꿍은 g. 이고, NM 짝꿍은 c., NP의 짝꿍은 p. 이다.

c. 영역에서 인트론을 표현할때 +, -를 사용한다.
위와 같이 인트론 전체 길이의 절반을 나눠서, 왼쪽 영역에 variant가 있으면 앞에 있는 엑손의 맨 뒷 코돈을 기준으로 몇번째 bp인지 +로 기재하고, 오른쪽에 있으면 뒤에 있는 엑손의 맨 앞 코돈을 기준으로 몇번째 bp인지 -로 기재한다.
(방향에 대한 정보가 없다면 암묵적으로 왼쪽이 5` 이고 오른쪽이 3` 으로 DNA 합성방향을 의미한다.)

3` 룰이라는게 있다. 이게 뭐냐면,
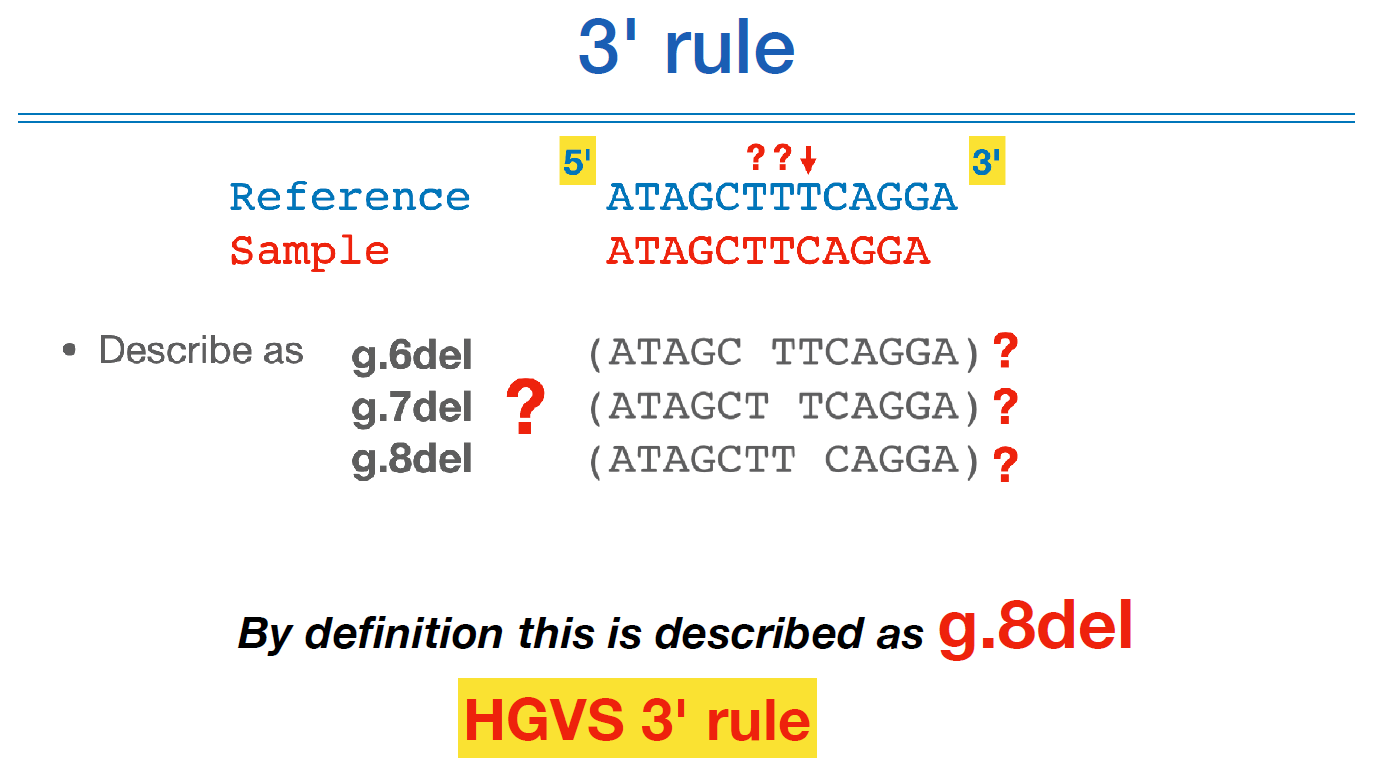
위 그림처럼 T가 반복서열이라면, 어떤 T가 빠졌는지 알수가 없는 것이다.
이런 경우는 3`쪽부터 시작한다. 제일 끝쪽이 deletion 되었다고 규칙을 정하여 g.8del (8번째 서열이 del 되었다) 로 표시한다. 이게 3` 룰이다.

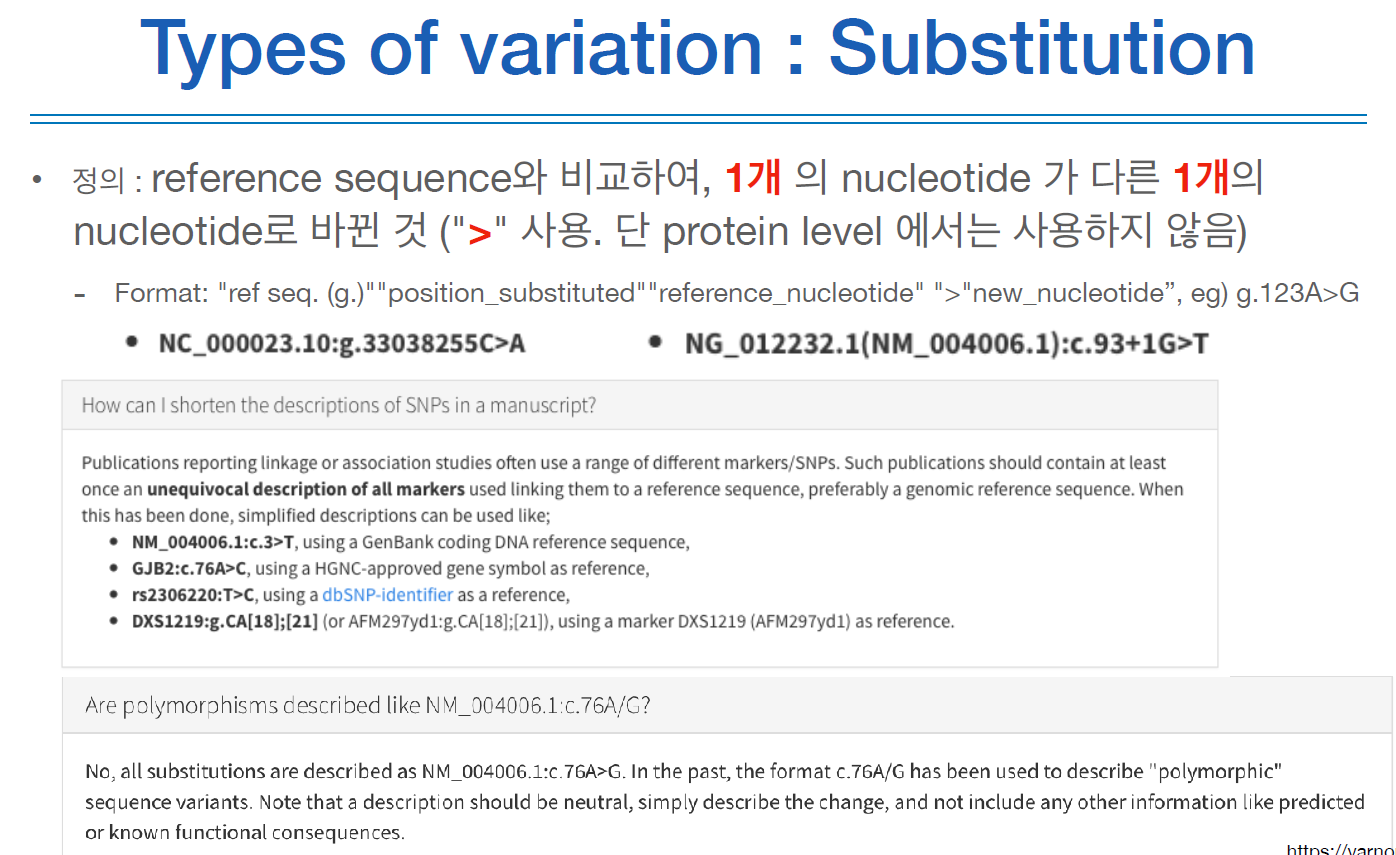
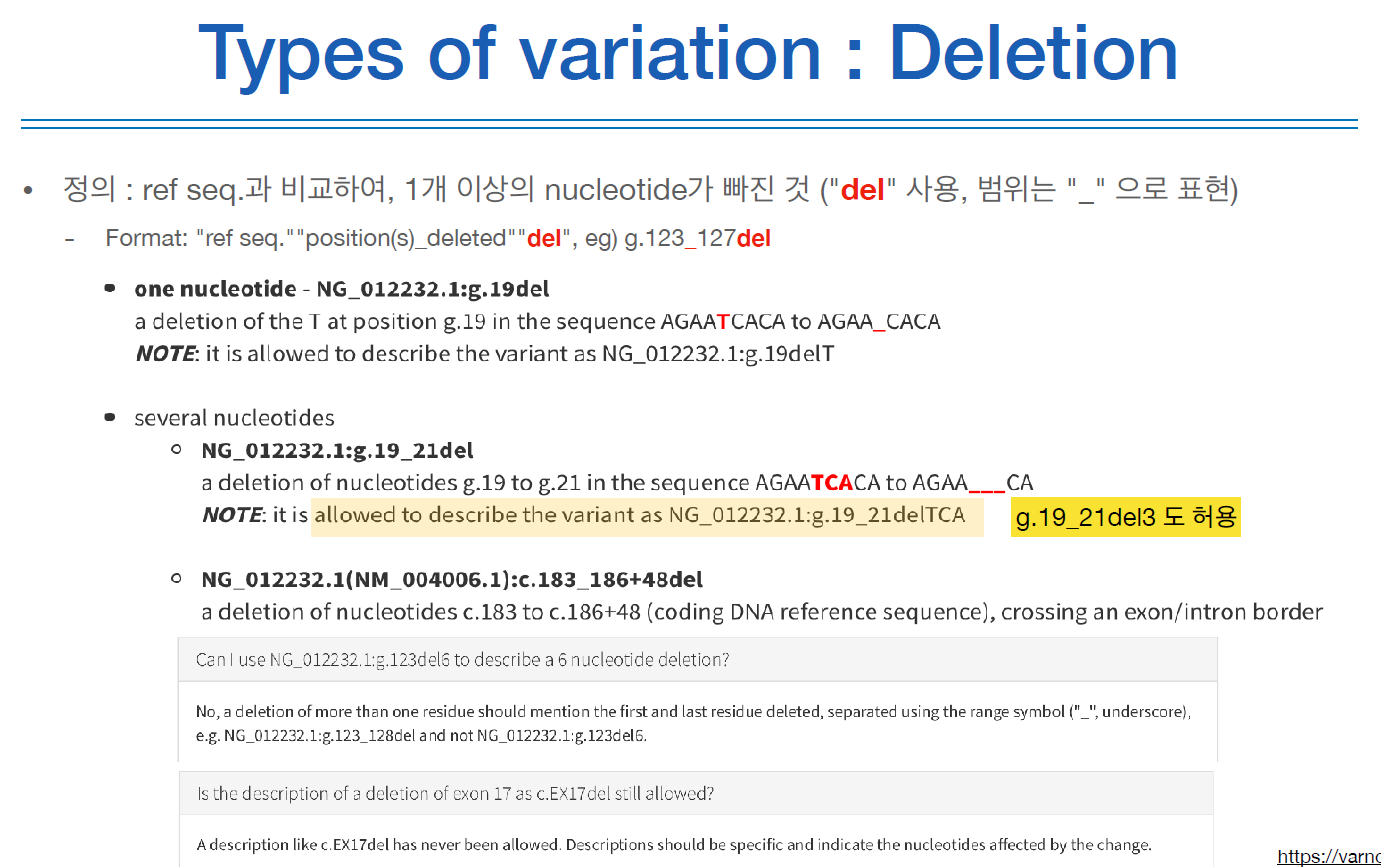
아래는 다양한 variation 타입을 표현하는 방법이다.






깜짝 퀴즈다! 이런 경우에 답은 무엇일까?

정답은 라. 이다.
insertion같지만 앞에 있는 서열이 T 이기 때문에 duplication 이다.
duplication은 레퍼런스 위치를 세는 것이기 때문에 6dup이 되는 것이다.
두번째 퀴즈!

정답은 다. 이다. 바뀐것이 없다는 표시만 해주면 된다.
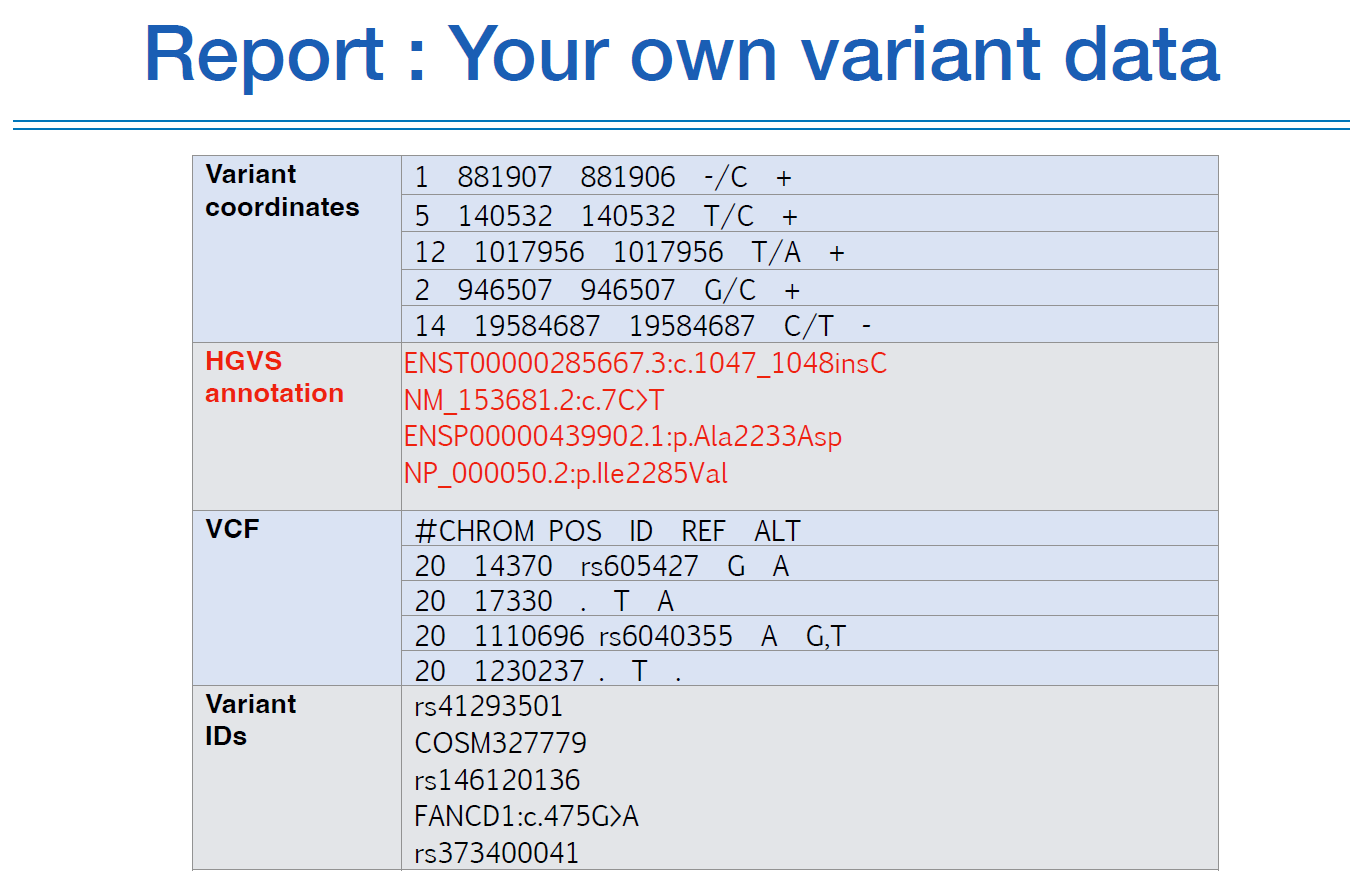
이 그림을 다시 보면, 이제 눈에 어느정도 들어온다는 것을 느낄 수 있을것이다.
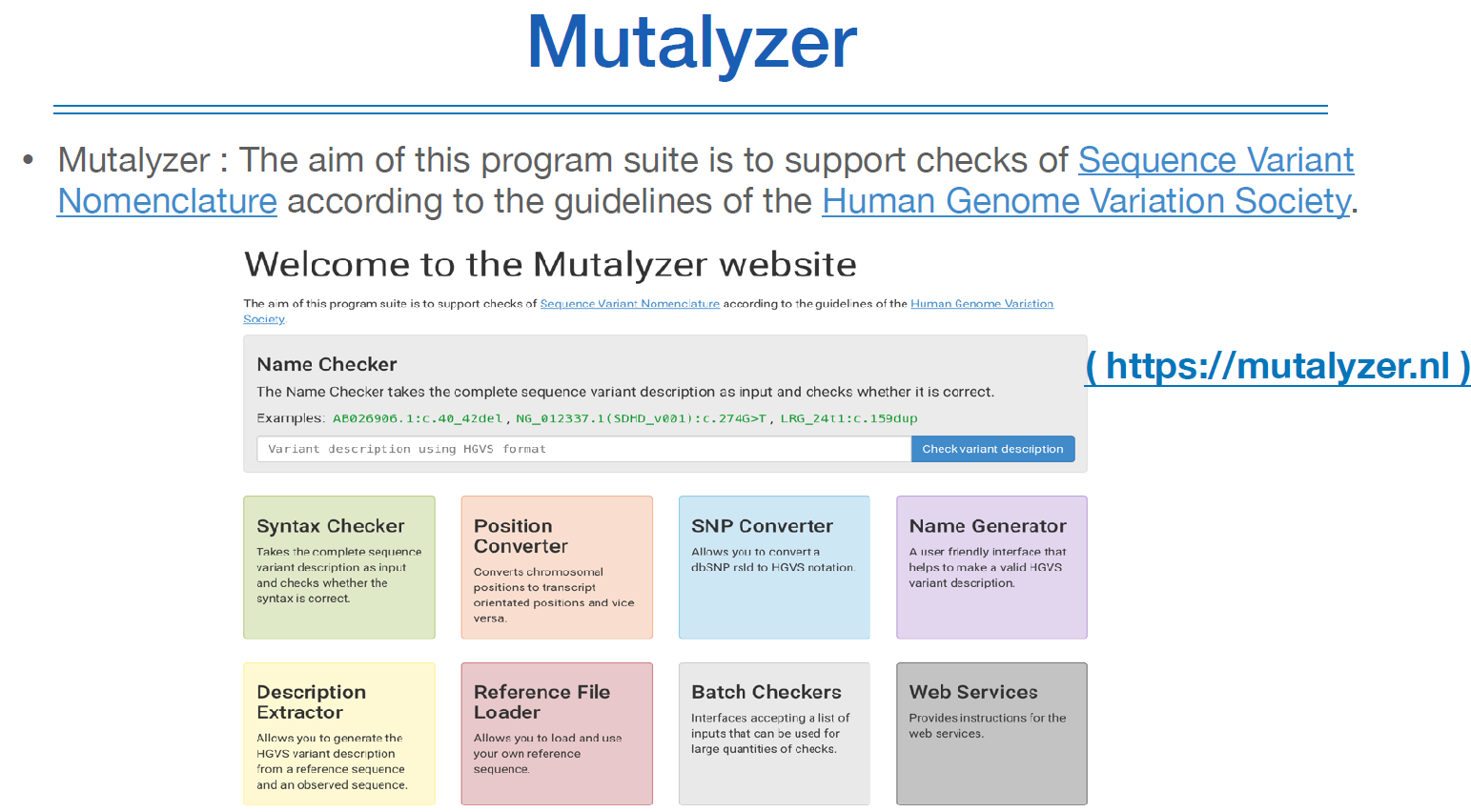
저런 것들을 내가 제대로 쓰고있는지 모르겠다면, 위 홈페이지를 가면 가이드라인에 따라, 내가 어떤 변이를 입력하면 잘 썼는지 아닌지 알려준다.
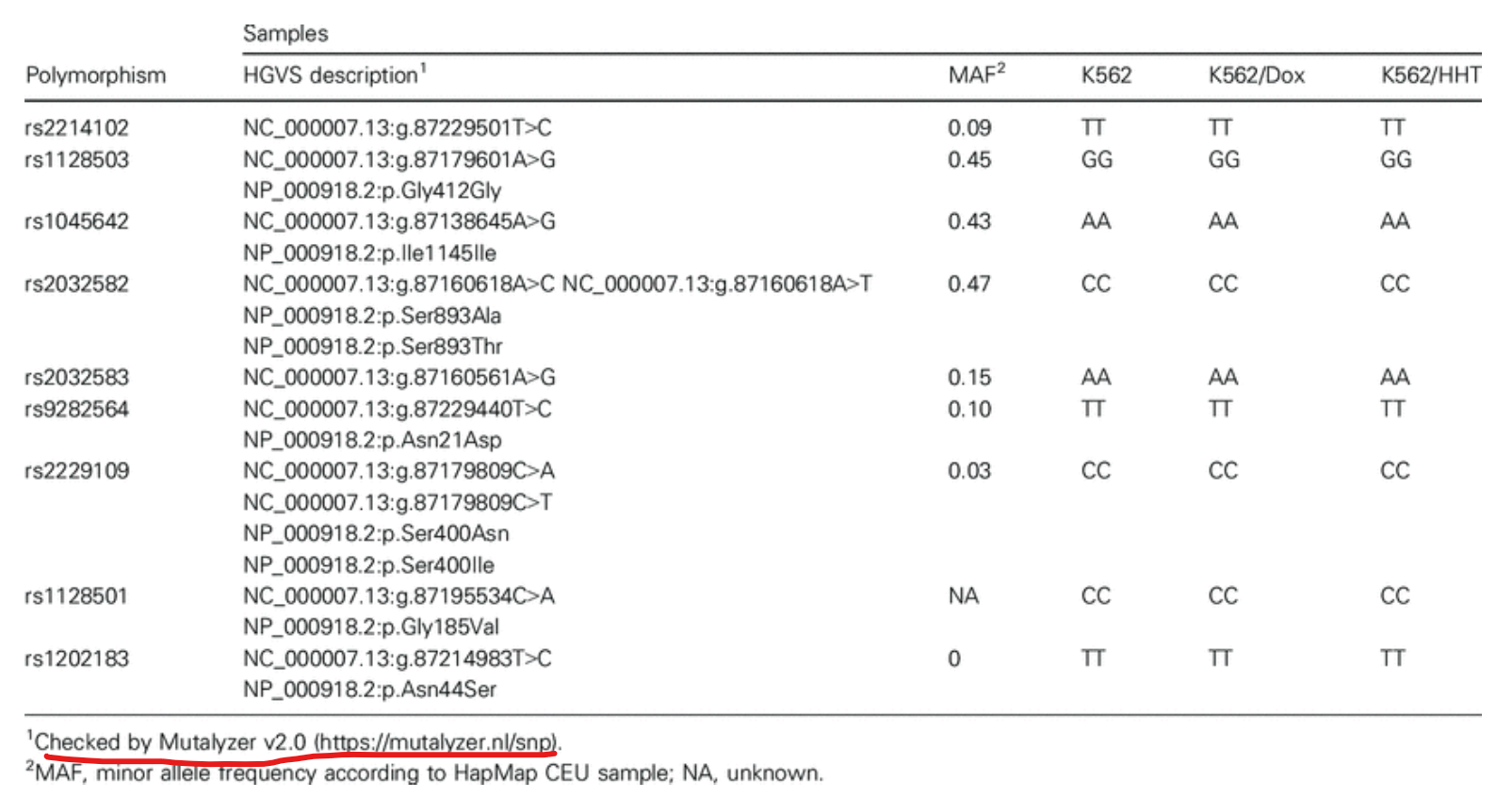
위 표처럼 mutalyzer로 명명법을 체크했다는 것을 표시해준다.

끝!
'medical' 카테고리의 다른 글
| [medical] 유전역학-9주차, 유전체 데이터의 해석과 질병 위혐률 예측 (0) | 2023.05.01 |
|---|---|
| [medical] 유전역학-개론, 8주차 암 유전체 연구 (0) | 2023.04.27 |
| [medical] 유전역학-개론 6주차, 차세대 시퀀싱(NGS) 데이터 분석 (1) | 2023.04.12 |
| [medical] 유전역학-개론 5주차, 유전체 시퀀싱 기술 (2) | 2023.04.05 |
| [medical] 유전역학-개론 4주차, 전장유전체 연관분석(GWAS) (2) | 2023.03.28 |



