
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데코레이터
- nfiti
- 확산텐서영상
- deep learning #segmentation #sementic #pytorch #UNETR #transformer #UNET #3D #3D medical image
- 파이썬
- genetic epidemiology
- precision #정밀도 #민감도 #sensitivity #특이도 #specifisity #F1 score #dice score #confusion matrix #recall #PR-AUC #ROC-AUC #PR curve #ROC curve #NPV #PPV
- monai
- Surgical video analysis
- parametric model
- paper review
- parrec
- 비모수적 모델
- nibabel
- MRI
- decorater
- non-parametric model
- MICCAI
- 유전역학
- tabular
- Phase recognition
- nlp
- 코드오류
- PYTHON
- TeCNO
- parer review
- 확산강조영상
- TabNet
- 모수적 모델
- words encoding
- Today
- Total
KimbgAI
[medical] 유전역학-9주차, 유전체 데이터의 해석과 질병 위혐률 예측 본문

이번 내용은 지난 8주차까지 배운 내용을 기반으로 해서, 질병 위험률을 예측해서 예방에 활용하고자 하는 내용이다.

질환과 관련된 변이들이 이렇게나 많이 보고가 되고 있는데,
무얼 더 찾기보다는 실제로 이런 것들을 활용해서 질병 예측을 해보자 하는 것이 본 주제이다.
이런 근거를 가지고 실제로 에측을 해보았을때 어느정도 예측할 수 있더라 하는 것이 결론이다.
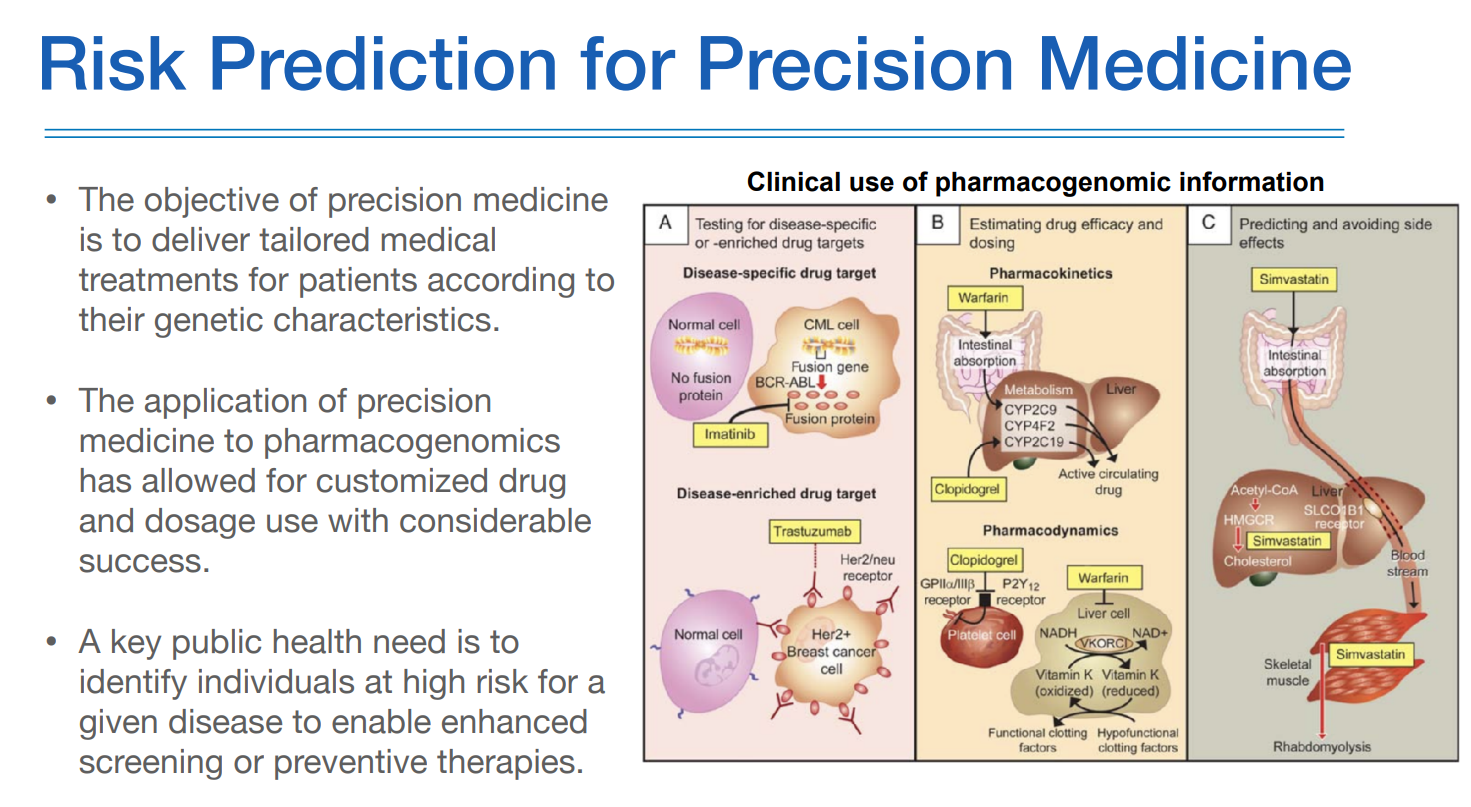
precision medicine 이라는 용어는 기존에 질병이라는 것에 대한 접근을 환자 또는 인구집단의 유전적 정보를 이용해서 질환을 다시 정의하고, 치료하고, 예측하고, 예방하는데 활용하겠다 하는 것이다.
암과 같은 경우에는 유전자 변이에 역할이 분명하고, 그것을 어떻게 처리하느냐에 따라 나오는 아웃컴이 명확하다.
하지만 complex disease 와 같은 경우는 polygenic trait을 가지고 있기 때문에, 몇몇개의 유전자만을 가지고 볼것이 아니며 하나하나의 변이의 이팩트가 매우 작기 때문에, 그 변이가 있더라도 질환이 나타나는 경우가 크지 않다.
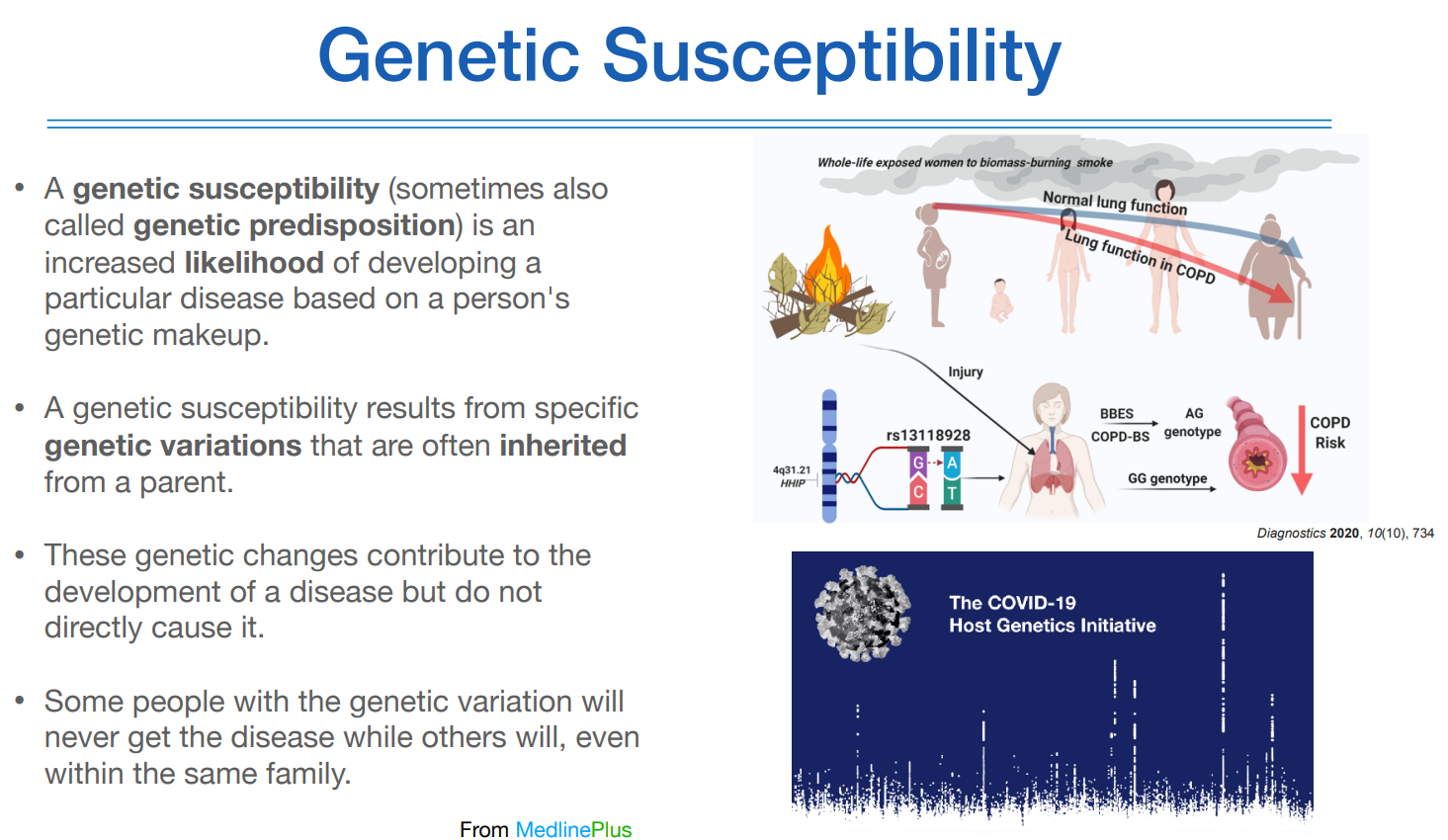
그리하여 이번 시간은 컴플렉스 질환에 대해 이야기를 할 것이다.
예측을 하려면 genetic susceptibility에 관한 이야기를 먼저 해야한다. 유전적 민감도 또는 유전적 소인이라고 한다.
어떤 질환이 발생할때 그 질환을 발생시킬 확률을 높히는 어떤 유전적 이팩트를 가지고 있다는 것을 의미한다.
유적역한 연구가 제대로 정립되지 않았을 때에는, 유전적인 요인이 아닌 환경적인 요인에 초점을 두고 역학 연구를 해왔다.
예를 들면, 똑같이 담배를 피는 사람인데도 어떤 사람은 COPD로 발현되고 어떤 사람은 건강한 케이스가 있는 것 처럼 말이다.
이러한 것을 설명하기 위해 위와 같은 개념이 등장한 것이다.
코로나도 마찬가지로, 같은 조건에서 코로나에 노출이 되었지만 어떤 사람은 걸리고, 어떤 사람은 안걸리고 하는 이유도 이에 해당한다.
또는 걸리더라도 누구는 중증, 누구는 경증으로 가는 상황 역시도..
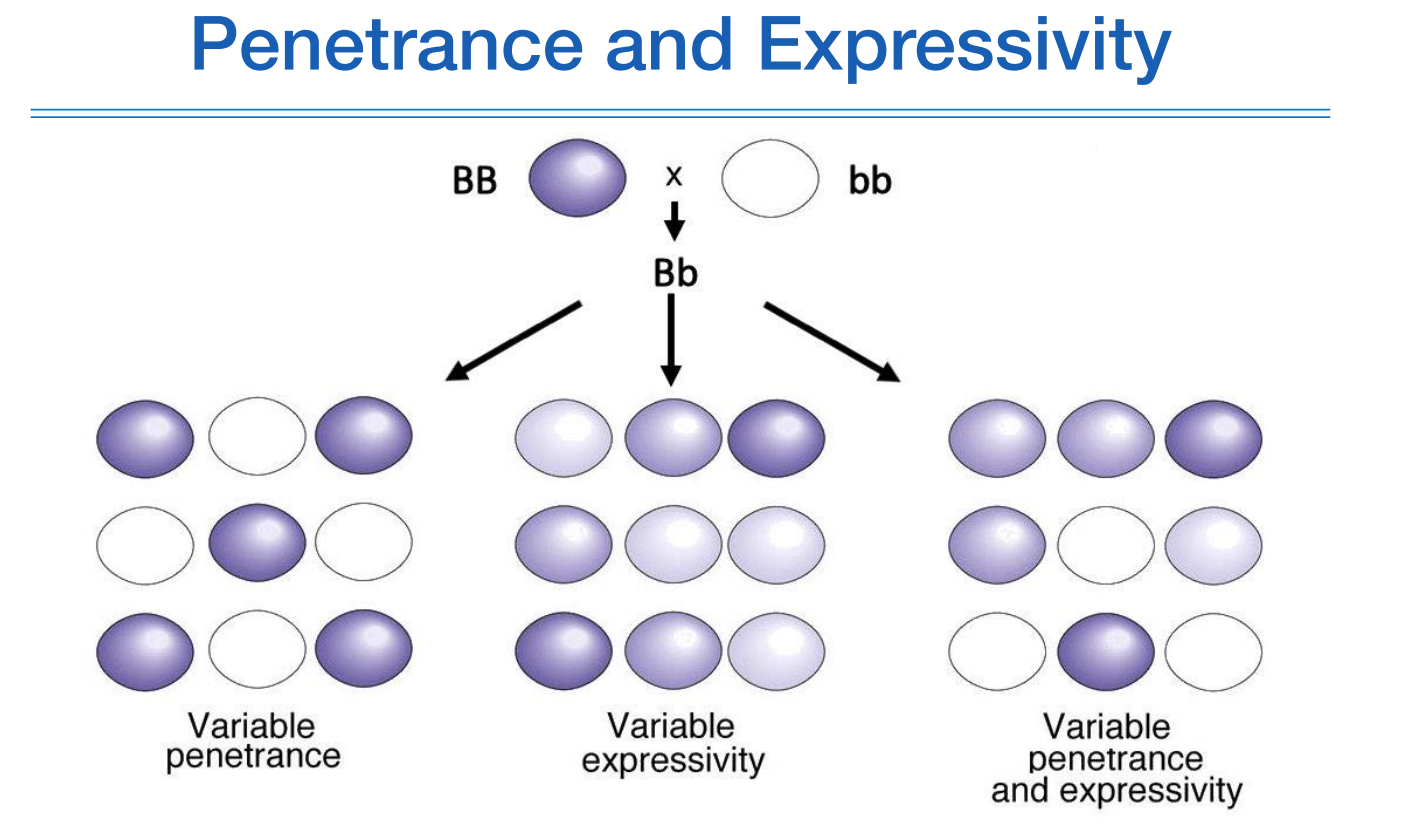
위 그림은 기초유전학할때 봤던 그림인데, 질환을 예측할때 penetrance와 expressivity의 개념이 중요하다.
B라는 변이를 가지고 있는 사람에게서 나타날수 있는 상황이 다양하기 때문에, 이 변이 하나만 가지고는 해당 질환이 나타날지 아닐지에 대한 예측이 어렵다.

지노타입 데이터로 연구를 할때 목적이 두가지로 나뉠 수 있다.
하나는 어떤 질환이 걸리기 전의 고위험군을 미리 찾아내어 분류하여 예방을 해보자 하는 것이다.
보통 심혈관질환에서 많이 활용이 되는데, 심장쇼크가 오기전에 미리 고위험군을 찾아내서 관리하는 것이다.
두번째 목적은 어떤 질환의 진단 기준이 명확하지 않은 경우 유전정보를 이용해 진단을 정확하게 해보자 하는 것이다.
멘델리안 질환 같은 경우 어떤 변이를 가지고 있으면 바로 거의 100% 예측이 가능한데, 반면 컴플렉스 질환은 어떤 변이를 가지고 있다고 해서 질환이 나타나는지 아닌지를 명확하게 이야기하기가 어렵다. 그래서 확률값으로 이야기를 해야한다.

구분을 잘 해야하는게, GWAS의 목적은 여러 스닙을 독립적으로 다 검증을 해봐서 해당 질환과 연관된 로싸이를 찾는 것이 목적이다.
그 로싸이를 찾았다고 해서 그것이 causal 변이는 아닐 수 있고 그 주변을 더 뒤져봐야 한다.(제네틱 마커를 사용하기때문에)
그 후 이 질환이 어떤 유전적인 영향때문에 나타나는지 기전 연구로 가는게 다음 스텝이다.
반면 에측이라고 하는 것은 단순히 질환이냐 아니냐만 구분하고자 하는 것이 목적이다.
어떤 것이 더 큰 위험요인이냐 하는 것을 알아내거나, 왜? 라는 것을 설명하는것이 목적이 아니고, 두 집단을 잘 분리하면 하면 좋은 예측 모델이 된다.
최근 사용하는 방법은 polygenic rick scoring과 머신러닝이 사용되고 있다.

GWAS 연구에 사용되는 변이들의 성격으로 나눈 그룹은 common disease에 영향을 끼치는 변이들은 보통 common한 빈도로 나타나며 이팩트 사이즈는 작다. 이러한 것들을 다 활용해서 예측연구에 활용한다.

이런 개념이 ploygenic risk score이다.(PRS)
작은 이팩트를 가진 변이들의 위험들은 조합하여 위험 점수를 산출한다. 그래서 해당되는 변이가 많을수록 높은 리스크를 가지고 있다고 말할 수 있다. 용어는 PRS, GRS 등 다양하게 불린다.

PRS는 크게 두가지 방법으로 구하는데,
먼저 질환과 연관되었다고 알려진 GWAS 결과에서 유의미하다고 나온 변이들 10개 정도가 나왔다면, 10개의 스닙의 이팩트있는 얼릴의 갯수를 더하면 된다.
이를 단순하게 더한 것이 unweighted PRS이고 각 얼릴의 가중치를 부여한 것이 weighted PRS이다.
PRS를 구하기 위해서는 두가지 데이터셋이 필요한데,
디스커러비 단계는 어떤 질환에 대해서 어떤 스닙이 영향을 끼치는지 보고된 기존의 GWAS연구 결과를 이용하여, 유의미한 스닙의 갯수를 정하여 PRS를 구하고, 얼마나 많은 스닙을 사용할 것인지는 PRS tuning 과정에서 정한다.
예를 들어 150개의 스닙을 사용했더니 가장 잘 질환을 설명하더라하면,
그 다음 단계인 밸리데이션 단계로 넘어가서 나의 데이터셋을 가지고 실제 검증을 해본다.
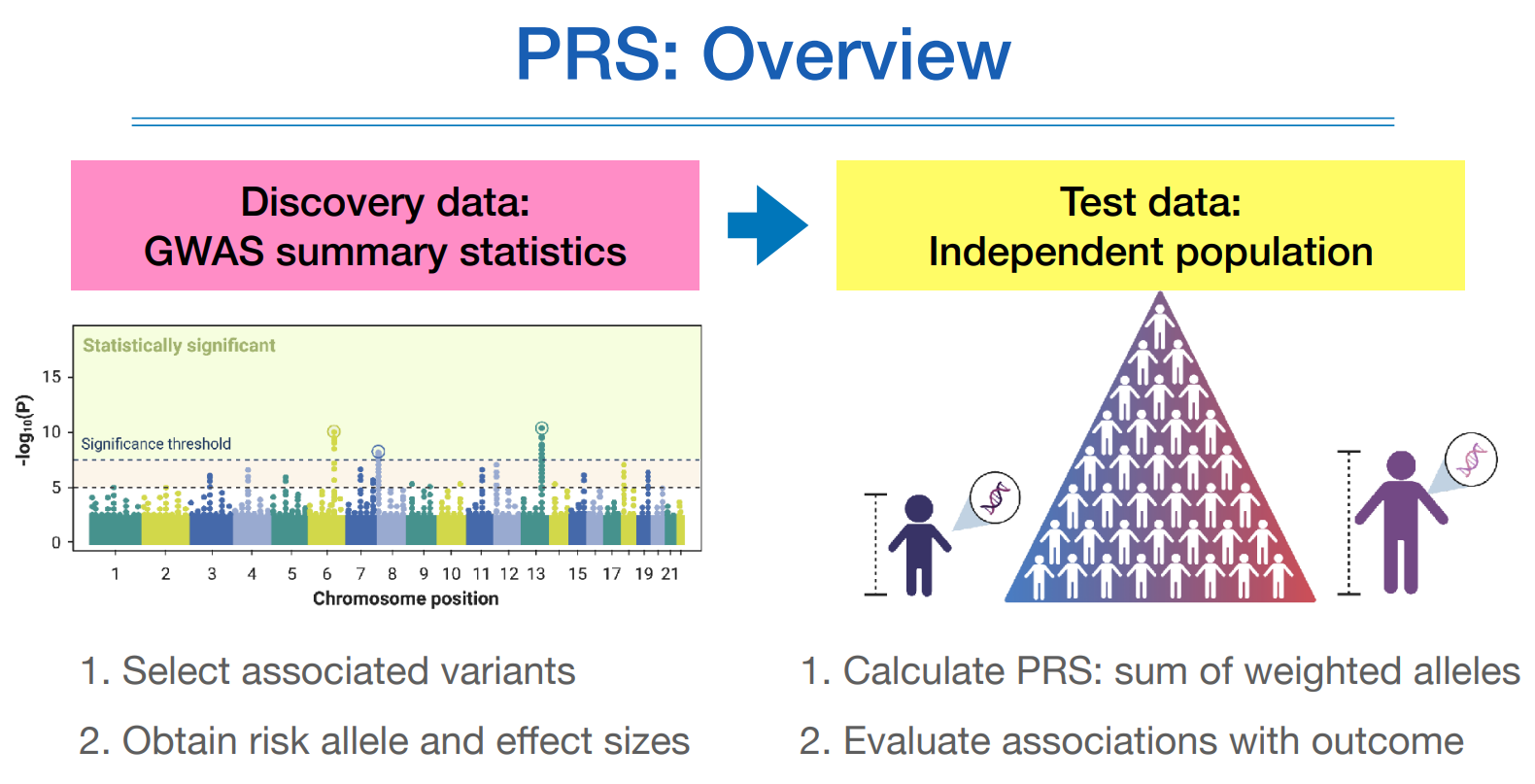
그림으로 보면 위와 같다.
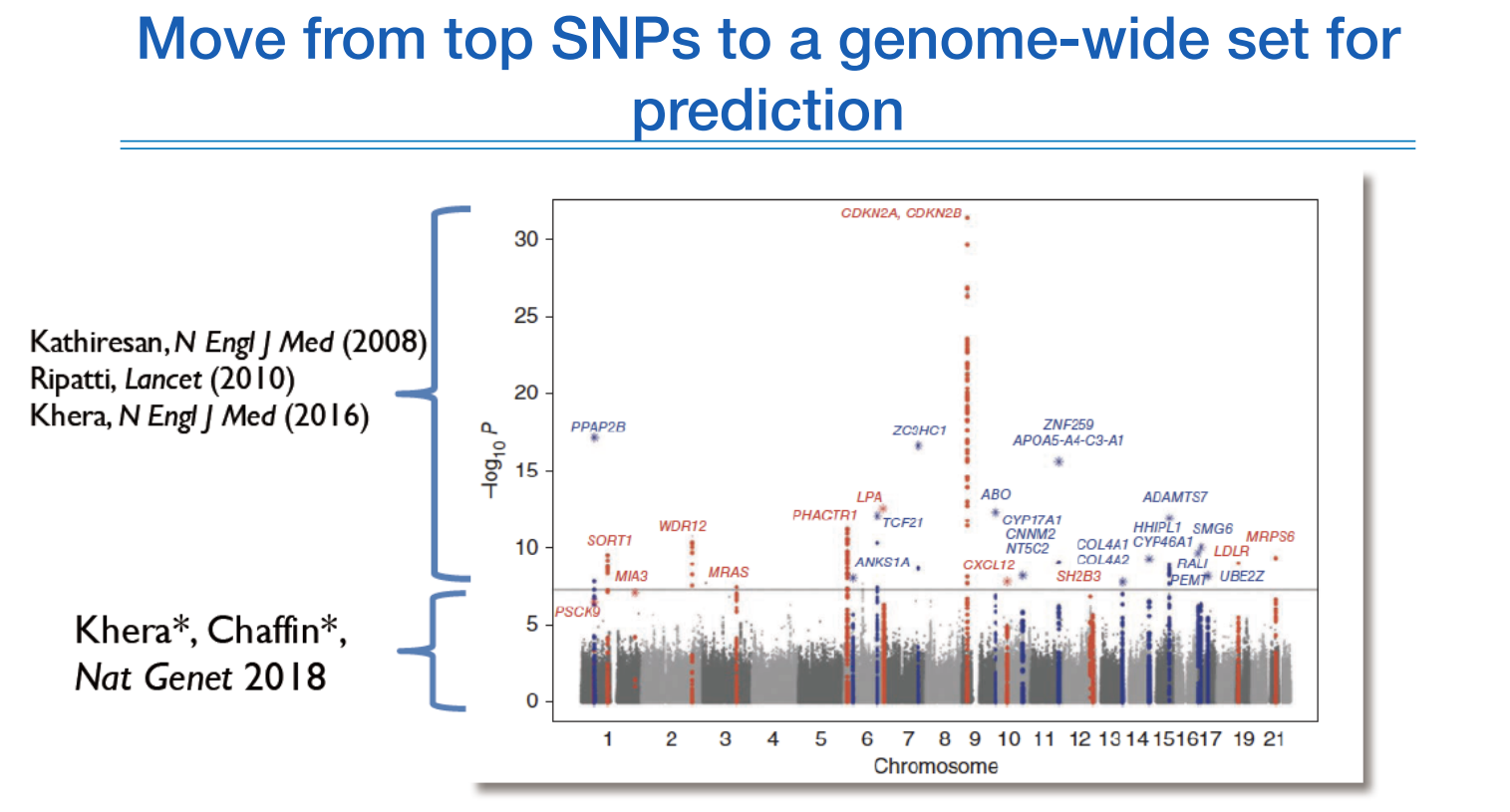
PRS를 초창기에 활용할때는 유의미한 것들만 가지고 예측을 했는데 생각보다 결과가 좋지 않아서, 최근에는 유의미하지 않은 것들도 포함하여 예측연구에 활용하여 좋은 결과를 내고 있다.
False positive인데도 불구하고 사용하는 이유는 prediction 성능을 높이기 위해서다. complex disease는 이런식으로 예측을 해야한다.
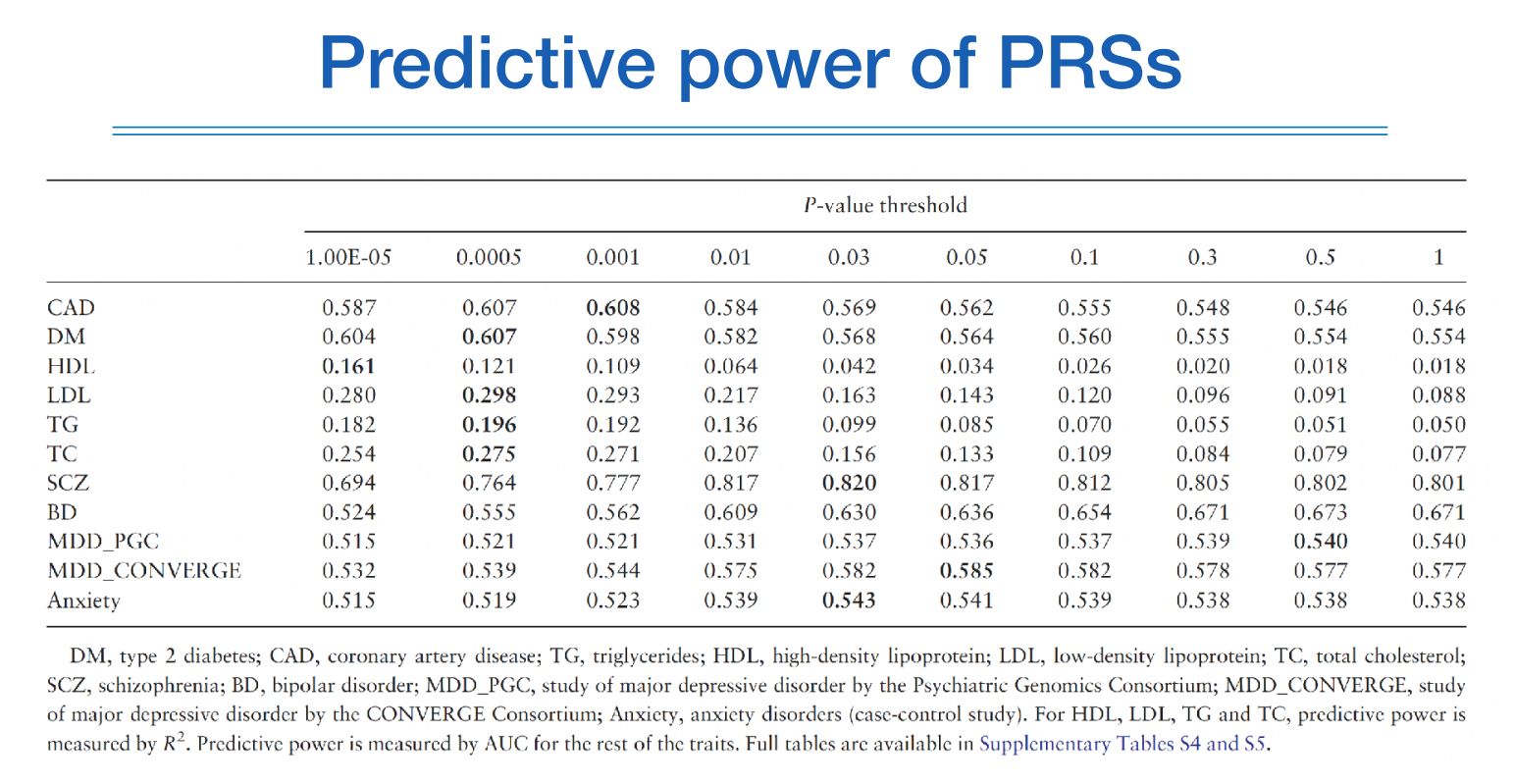
그렇다면 얼마나 많은 변수를 넣어야하는가? 하는 질문에는 어떤 질환은 예측하고 싶으냐에 따라 다르고 실험값에 해당한다. 위 그림처럼 질병에 따라 p-value의 기준을 달리하여 AUC를 산출한 결과인데, 질병에 따라 결과가 다양하지만 대체로 기존의 엄격한 p-value보다 낮은 수준에서의 p-value를 가진 스닙들도 포함하니 성능이 향상된 것을 확인할 수 있었다.
또한 이것을 가지고 알 수 있는 것은 해당 질병에 관여하고 있는 스닙이 얼마나 많은지를 간접적으로 알 수 있다.
HDL보다는 MDD_PGC라는 질환이 보다 많은 스닙을 사용했을때 AUC가 올라갔고, 이는 다른 말로 하면 더 많은 스닙이 해당 질환에 관여하고 있다는 것을 알 수 있다.
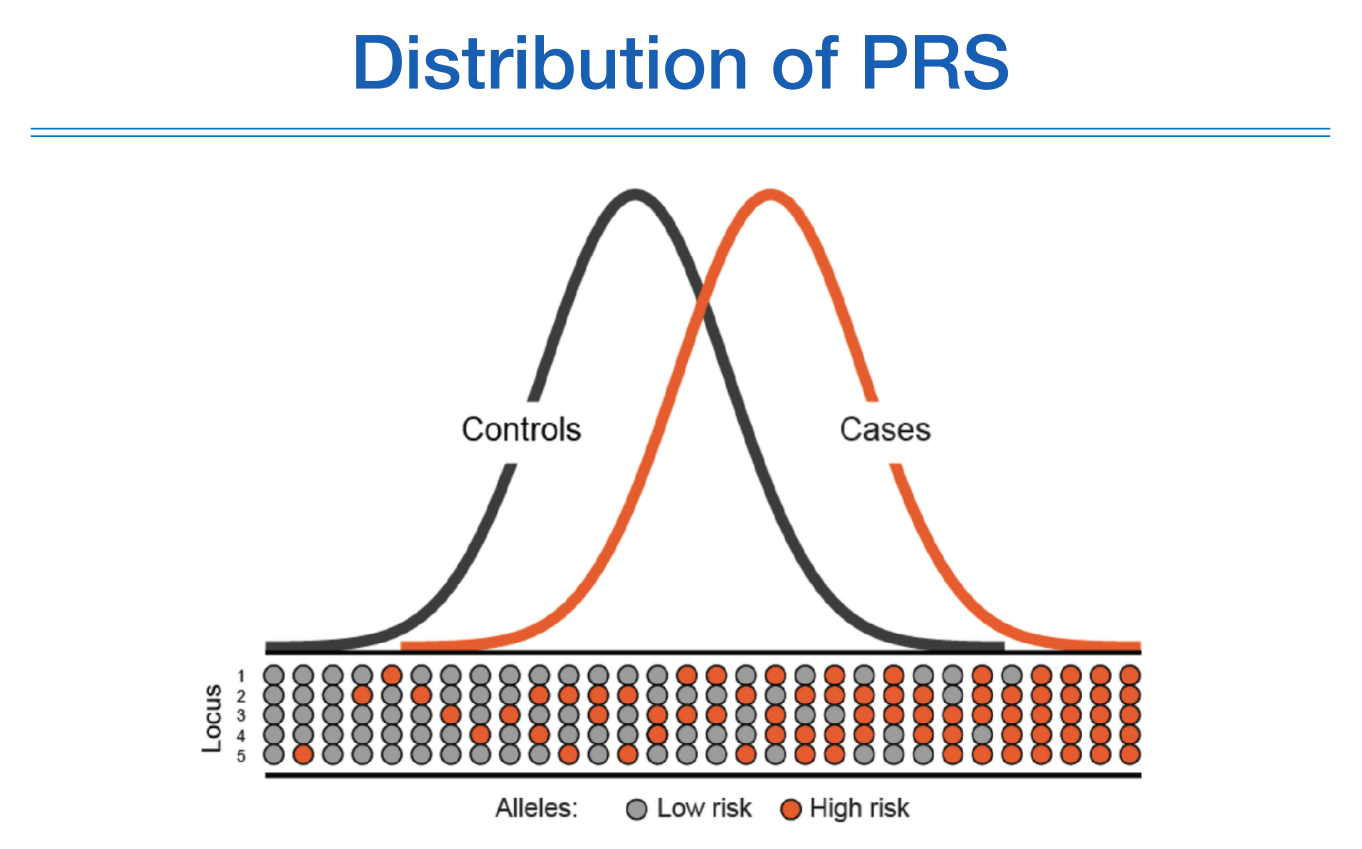
한 명당 해당 질환에 대한 PRS를 구하면 보통 정규분포를 띄게 되고, Controls의 PRS 평균값보다 Case의 PRS 평균값이 높게 나온다.
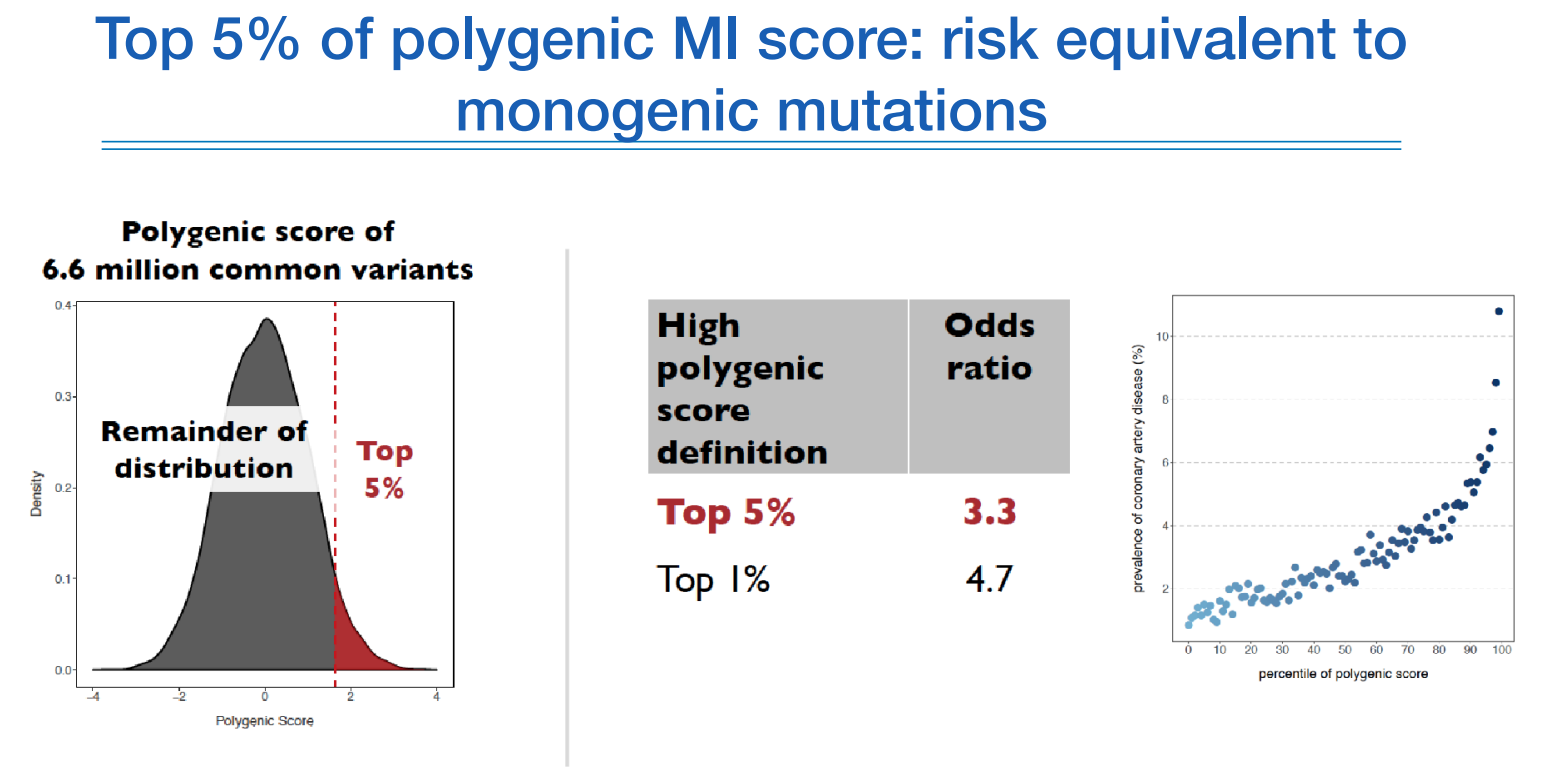
심근경색(MI)의 스코어를 보면 PRS가 높은 상위 5%의 사람들은 그렇지 않은 사람보다 오즈비가 3.3배 이상 높은 위험도를 가지고 있고, 이 사람들은 사전에 분류하여 관리하면 intervention이 가능할 것이다 라고 보고 있다.
이런 3~5배 수준의 수치는 굉장히 높은 수치이며, 이정도의 수치는 멘델리안 질환 정도의 수준이다.
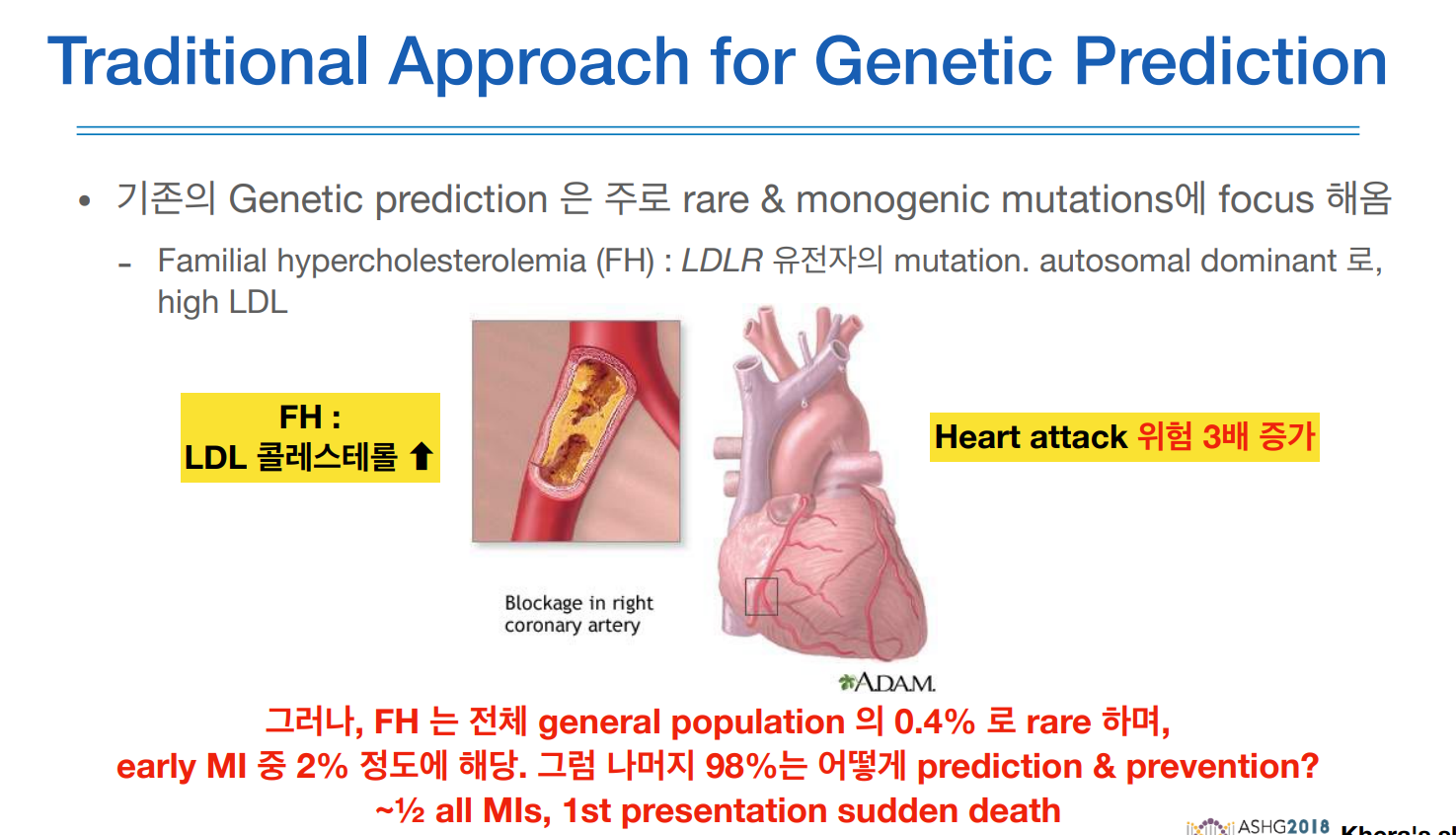
위와 같은 경우에도 0.4% 수준의 rare한 변이인 FH를 가지고 있다 할지라도 심근경색에 일반적인 사람보다 3배정도 위험 수준을 보이며 early MI 중 2%에 해당한다. 나머지 98%를 예측하는데에 이런 PRS가 활용할 수 있다.

monogenic 보다 high polygenic으로 좀더 많은 사람들을 예측할 수 있다.
또한 해당 질환을 가진 사람의 genetic population은 변하는 것이 아니기 때문에, 이른 나이에서의 위험도 역시 파악할 수 있다.
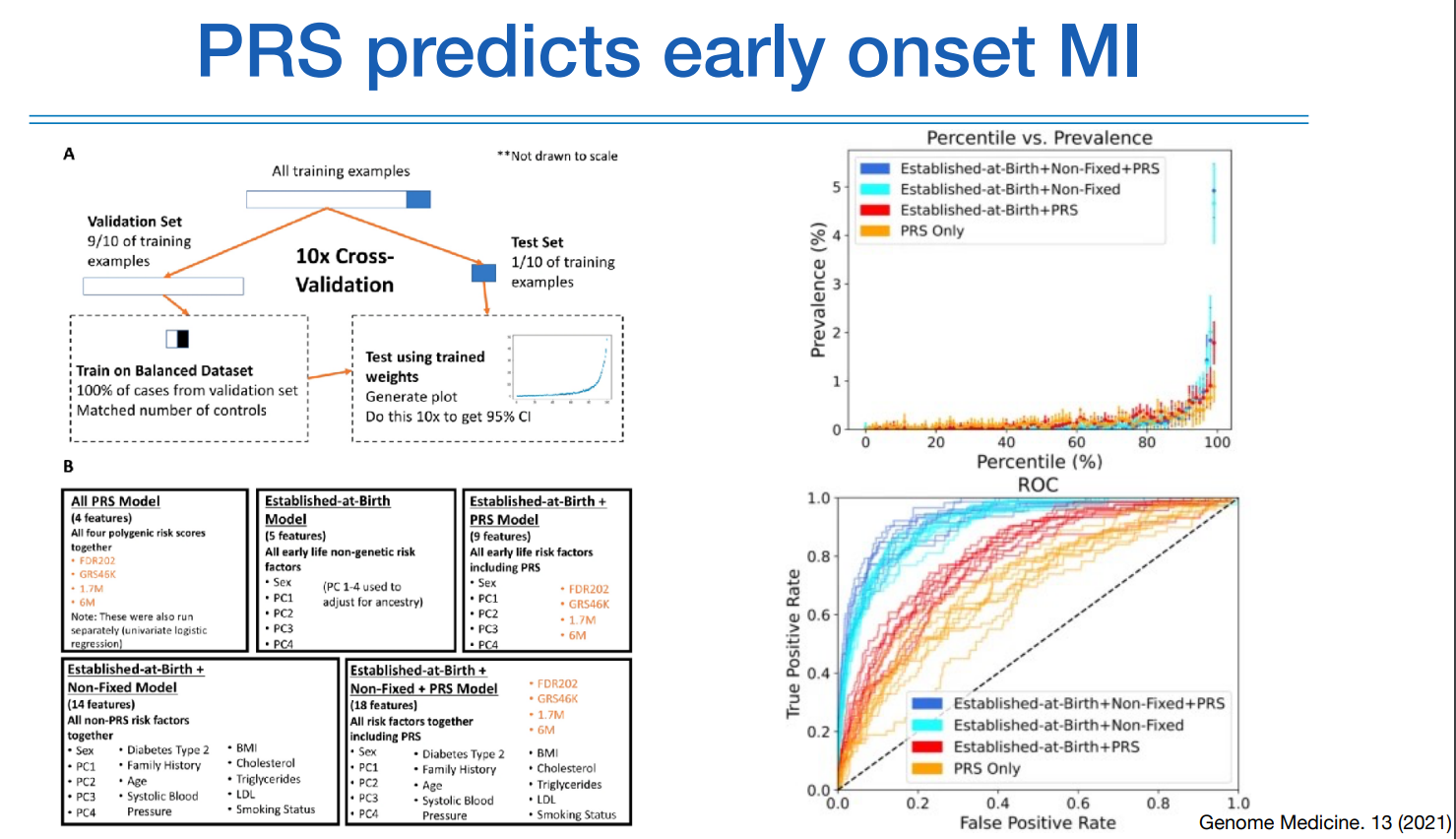
위 그림을 보면 MI에 대한 예측을 다양한 인자들을 사용하거나 하지 않거나 하는 조합으로 예측한 연구이다. 다양한 인자는 PRS, 태어나자마 알수있는 정보이며 변하지 않는 인자인 성별&인종과 같은 변수, BMI 또는 나이와 같이 변하는 변수 등이 해당된다.
당연하게도 모든 변수를 활용했을때 ROC-AUC가 가장 좋았고, PRS만 가지고도 높은 수준의 결과를 나타냈다.

PRS의 한계점은 additive effect, 즉 질병과 PRS가 선형관계임을 가정하는 것인데 실제로는 그렇지 않으며 PRS간의 다중공선성이 있을 수 있다는 모델링 자체의 제한점이 있다.
그리하여 최근에는 이런 제한점을 극복하기 위해 AI, 머신러닝, 딥러닝과 같은 방법론을 사용하고 있다.

어떤 상황일때 머신러닝을 통한 분석이 더 좋은지 heritability를 통해 설명하자면,
CD나 T1D 과 같은 경우는 immune disease라고 하는데 이는 일반적으로 알려진 complex disease보다 높은 heritability를 가진다 또 다른 특징은 큰 유전적 소인을 가지고 있다는 것이다. 다양한 변이가 관여하는 것이 아닌 일부 변이가 큰 영향을 미친다. rare disease는 아니고 그것보다 많은 변이가 관여하긴 하지만 특정 영역에 있는 변이들이 영향을 크게 미친다는 것이다. 그렇게 때문에 모델링을 할때 이러한 정보를 알고 관련된 변이들을 넣으면 더 높은 예측성능을 얻어낼수있다.
반면 CVD같은 경우는 그보다 적은 heritability를 가지기 때문에 넓은 범위의 다양한 SNP을 넣어서 연구하는 것이 좋다.

PRS와 머신러닝 방법의 장단점을 위와 같다.
PRS와 머신러닝은 단순히 문제를 풀기위한 도구일 뿐이지 우열을 가릴수는 없으며 상황에 따라 적절히 선택해야한다.
PRS는 단순하며 해석하기 쉽지만, 복잡한 관계를 설명하기 어렵다.
이런 단점을 보완하는 것이 머신러닝의 장점이지만, 해석하기 어렵고 많은 더 데이터를 필요로 한다.
아래는 머신러닝에 대한 내용이기 때문에 별다른 설명없이 슬라이드로 대체한다.


L1 정규화는 중요하지 않는 feature는 0으로 만들고 L2는 그런 feature를 0으로 상당히 가깝게 만든다.
단순한 것을 좋아하기 때문에 L1을 보통 많이 사용한다.

이 연구의 목적은 CD에 대해 진단 자체를 제대로하지 못했기 때문에 제대로 진단을 잘 해보자 하는 것이 목적이다.
기존의 복잡하고 전통적인 방법의 AUC 결과는 0.85 수준인데 반해 머신러닝을 활용한 AUC는 0.9로 CD를 예측할 수 있었다.

이 연구의 목적은 앞선 CD와 다르다. 이 연구의 목적은 검사 시점 당시에 CVD가 아닌 환자를 찾아내서 preventive intervention하는 것이 목적이다. 기존에 밝혀진 scoring system에 PRS를 추가하여 고위험군을 찾아내보자 하는 것이 목적이다.
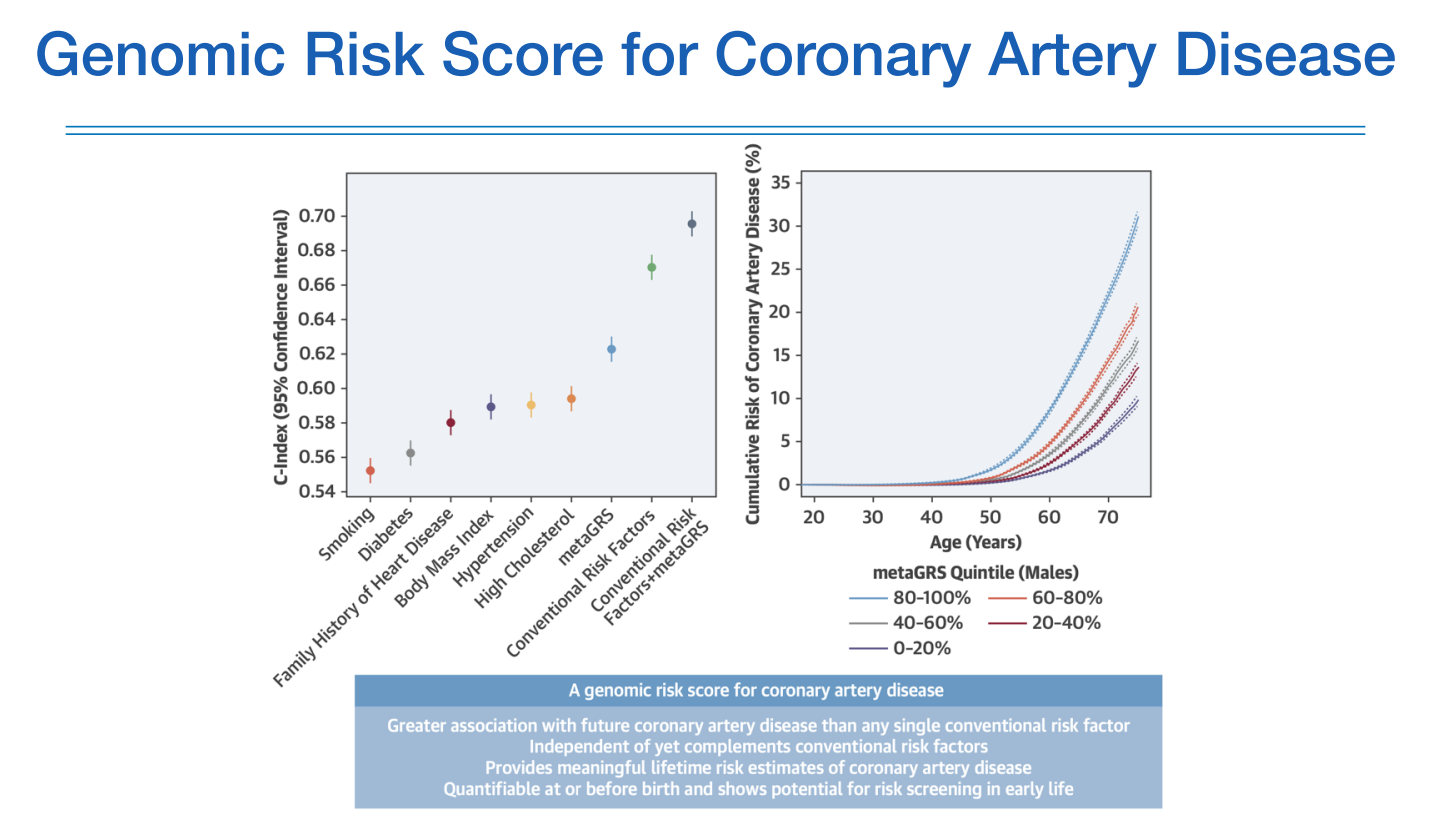
여기서는 PRS를 GRS로 표현하고 있는데, 기존에 CRF(conventional risk factors)에 PRS 더하였더니 조금더 높은 C-index를 보였고, 더불어 위험도에 따른 quantile에서 상위 20% 그룹이 보다 젊은나이(50대부터)에 특징이 두드러지기 시작한다.
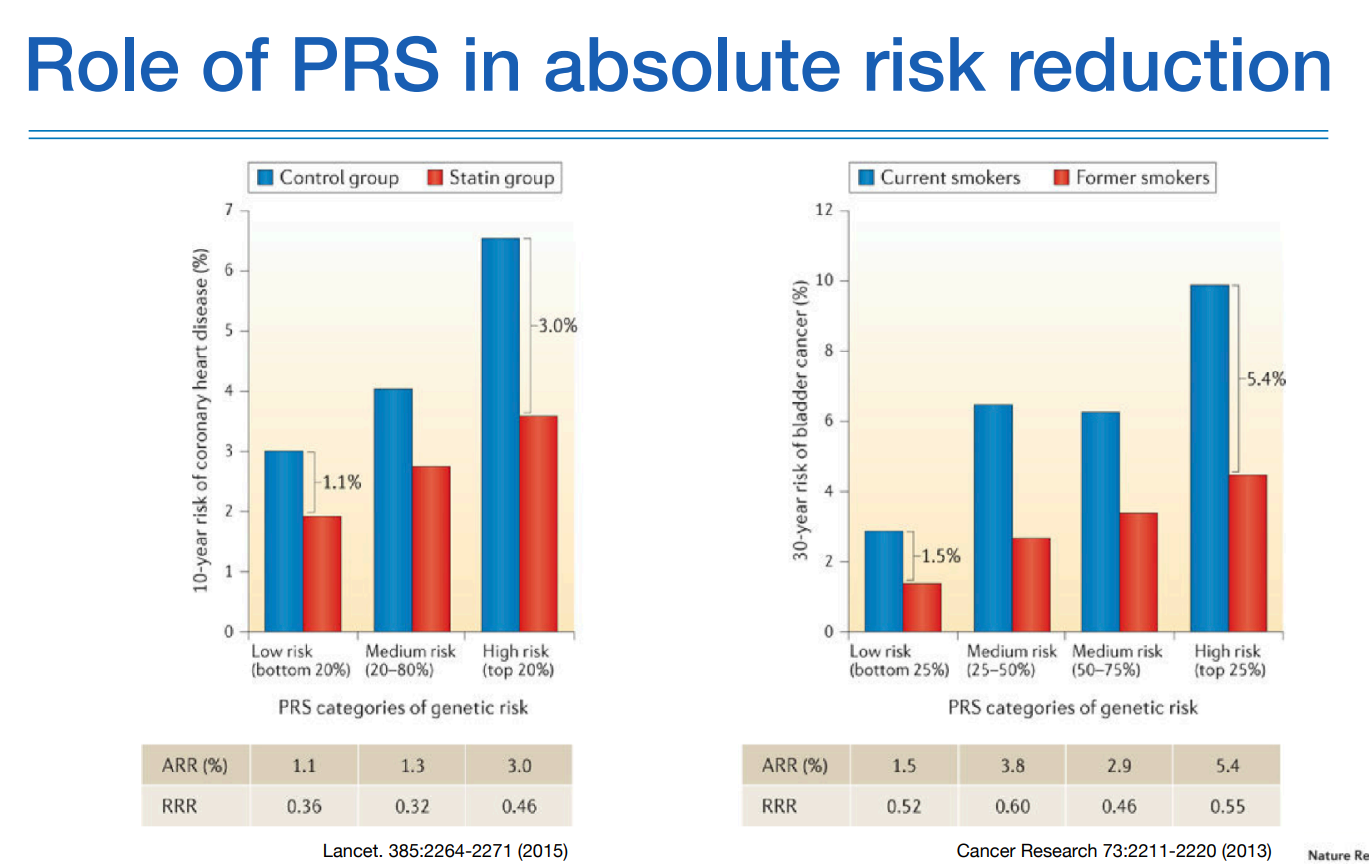
위 그림에서 왼쪽 그림을 보면 고위험군에서는 저위험군보다 intervention을 했을때 거의 3배정도의 효과를 나타냈고, 우측 cancer와 같은 경우에도 고위험군이 저위험군보다 더 높은 효과를 확인했다.
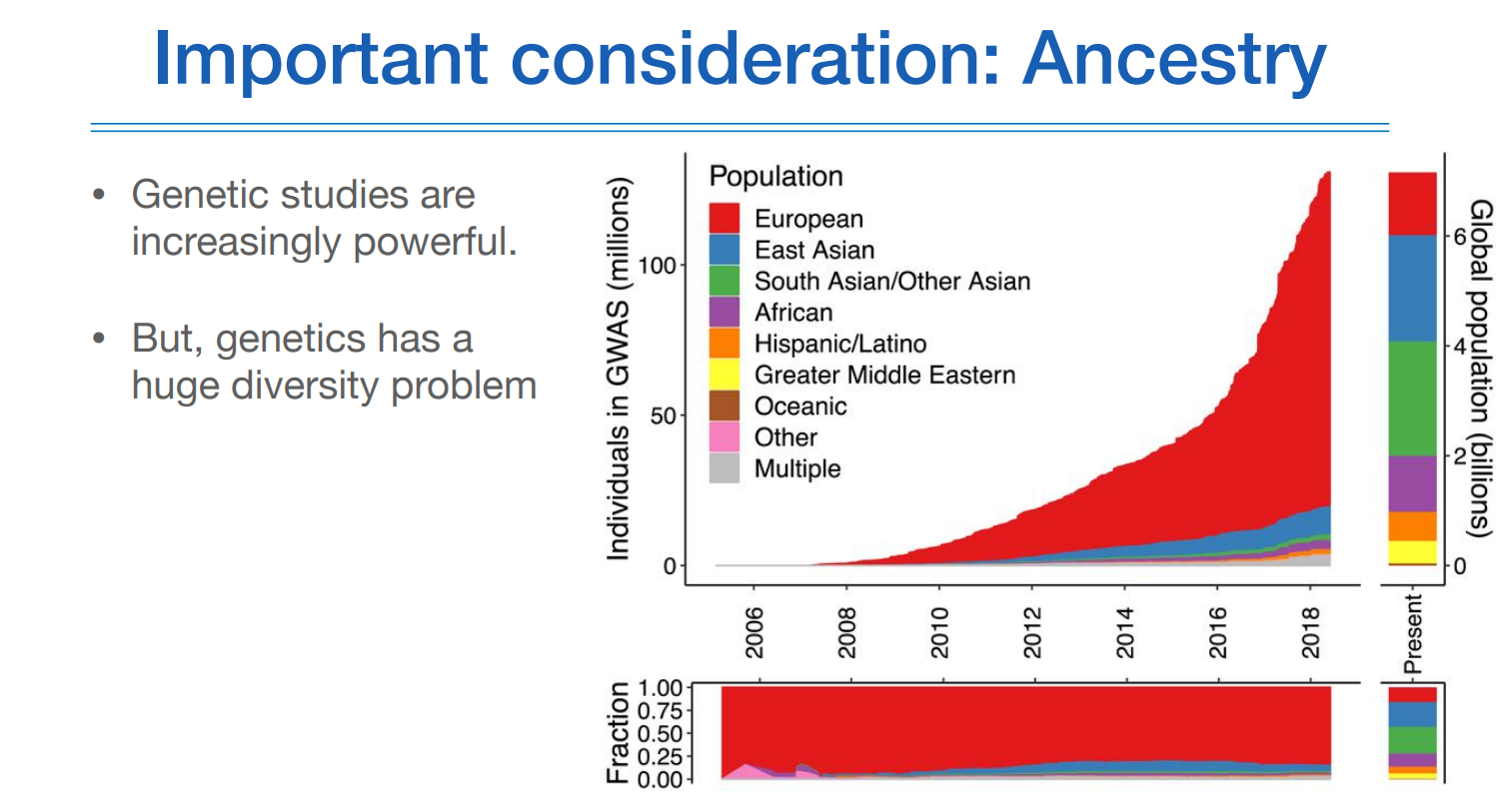
기존에 알려진 연구결과가 많기 때문에 이런 연구결과를 활용해서 예측해보고자 함인데, 기존에 알려진 연구결과는 대부분 유러피안이다. 이 유러피안 데이터가 과연 우리 한국인을 잘 예측할 수 있을까 하는게 요즘 이슈이다.
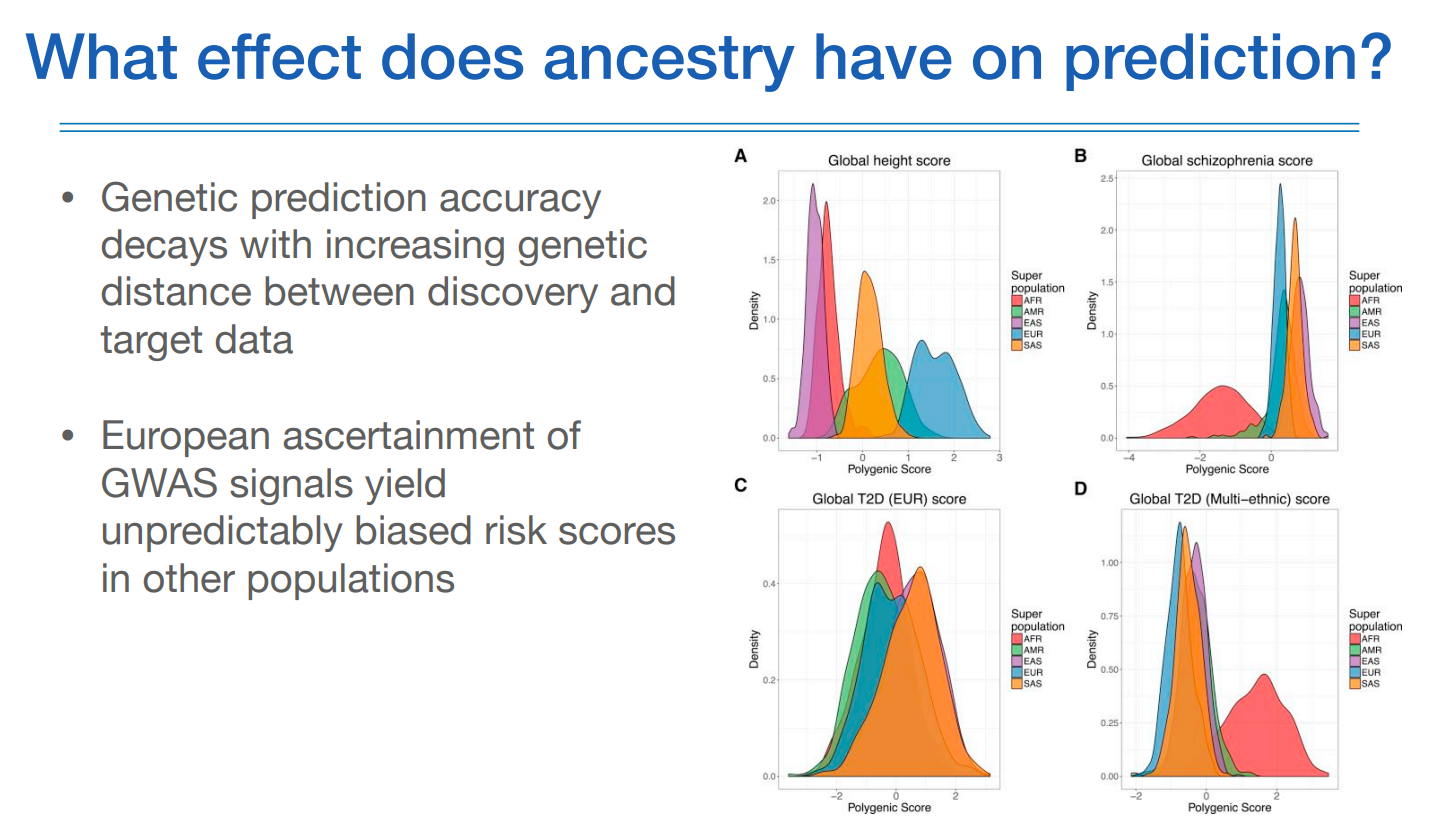
PRS의 인종별 분포를 보면 다 다르다.
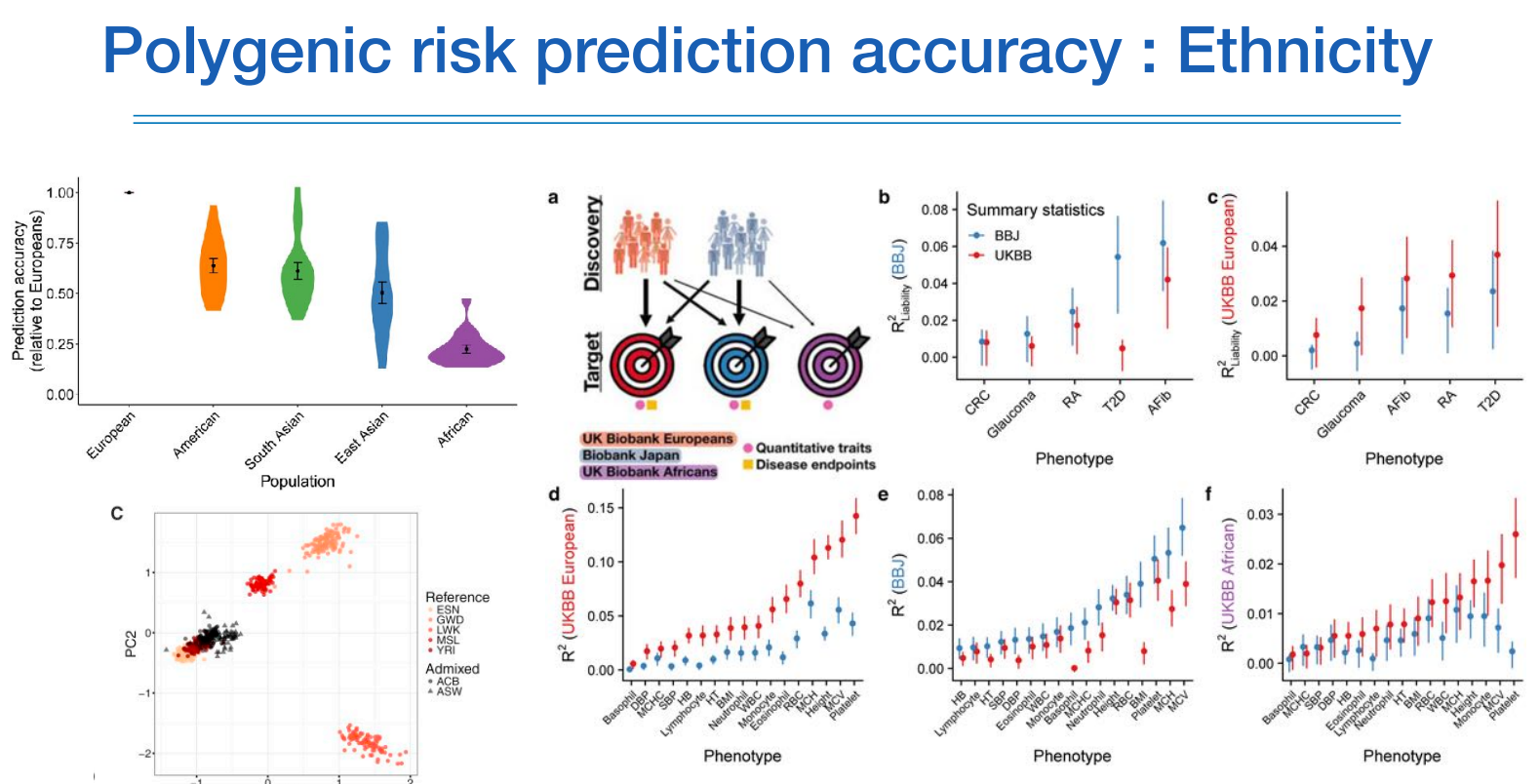
위 그림에서 좌측 상단 그림에서은 유러피안에 대한 정확도를 1로 봤을때 다른 인종에 대한 정확도는 그보다 더 떨어지는 것을 볼 수 있고, 유전적 복잡도가 가장 높은 아프리칸계 인종의 정확도가 가장 낮다.
다른 그림도 비슷한 현상을 설명하고 있다.
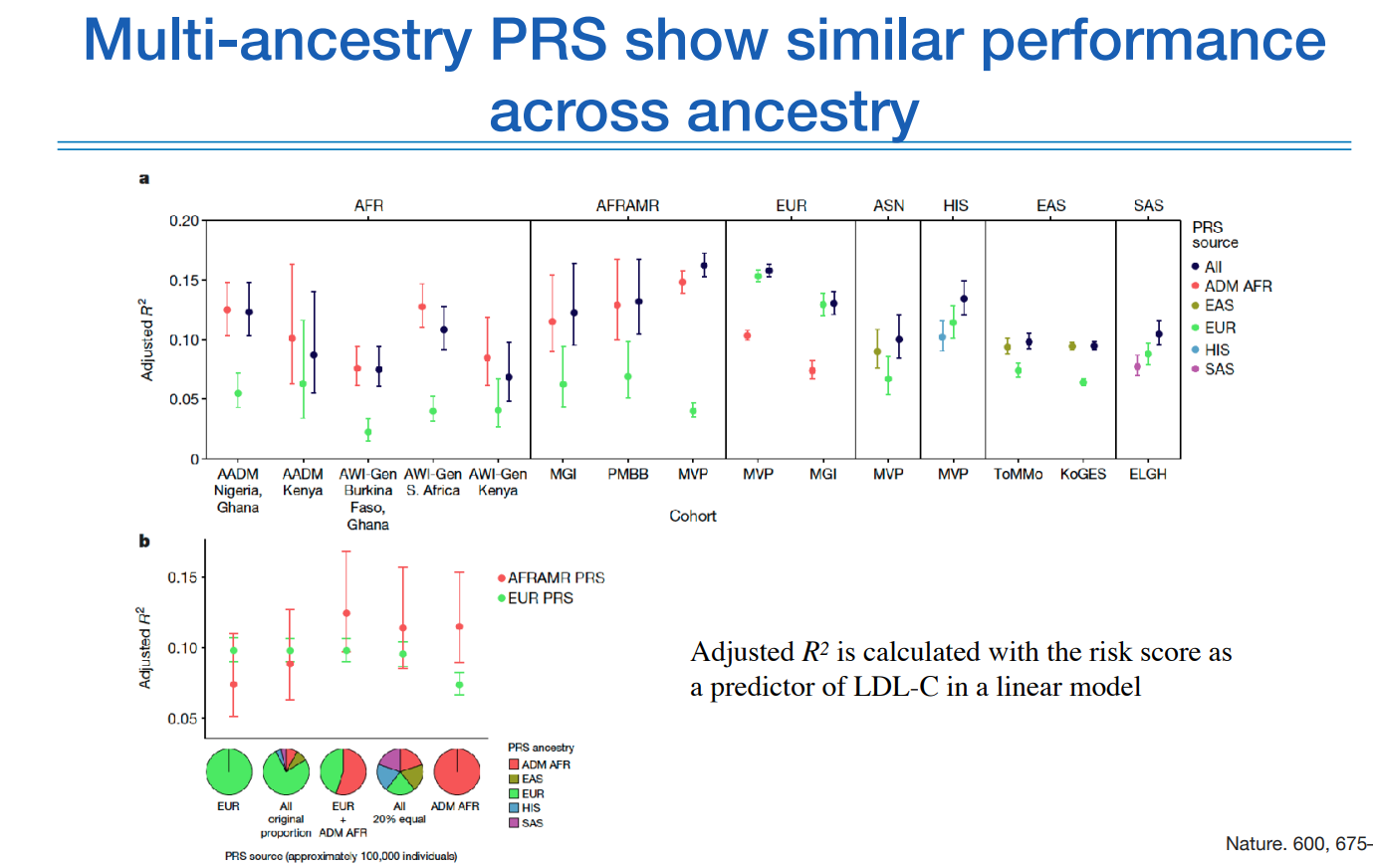
여기까지가 PRS와 관련된 이야기다.
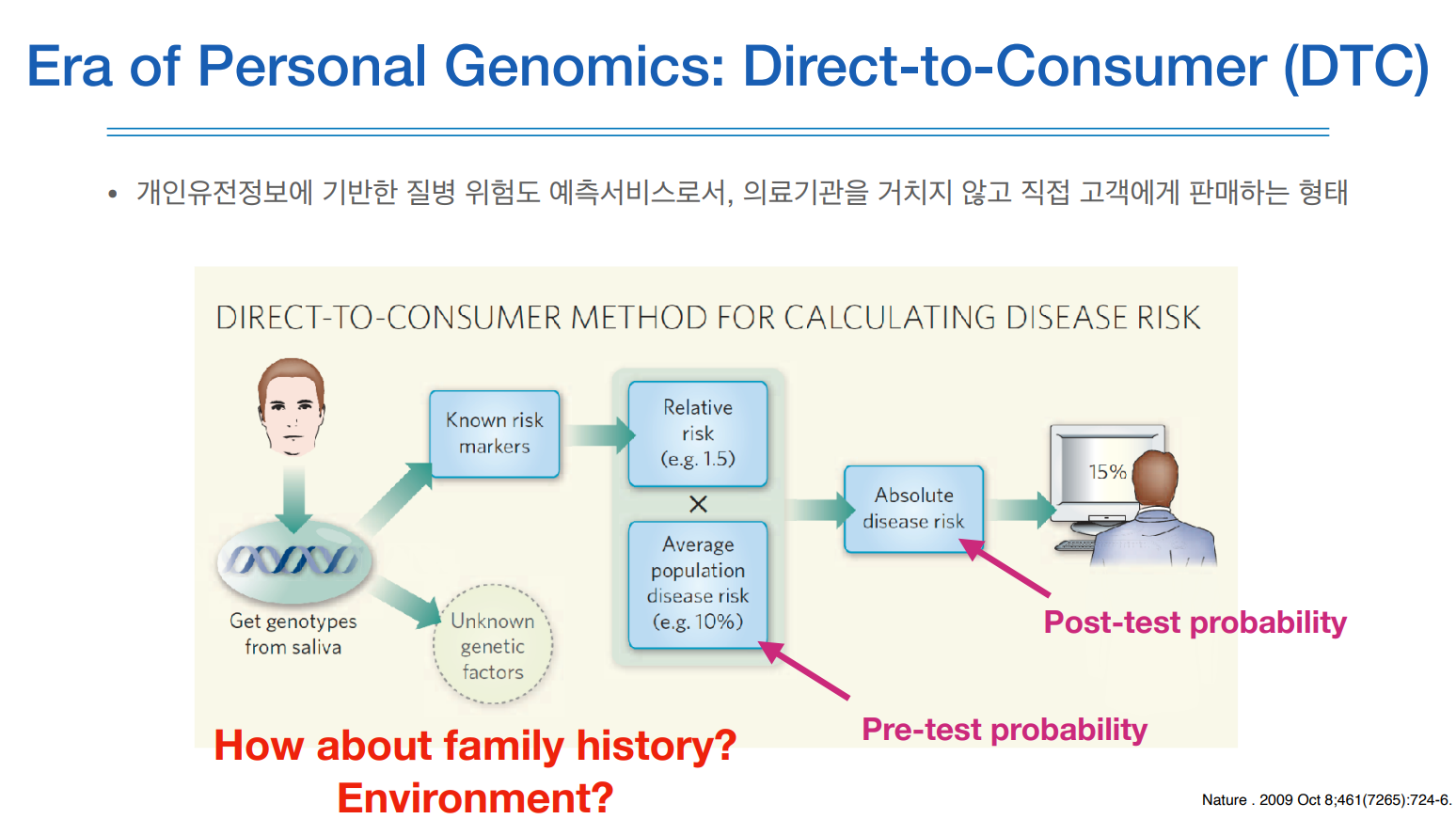
유전적 정보들을 이용해서 실제로 질환을 예측하는 서비스를 하는 것을 DTC라고 한다.
인터넷으로 신청을 하면, 약 100달러 정도?, 키트가 오는데 거기에 침을 뱉어 밀봉하여 반송하면 회사에서 지노타이핑을 하여 알려진 마커에 대해 질병 관련 위험도를 알려준다.
이런 서비스의 위험은 어떤 질병에 대한 위험을 과대평가하여 스스로의 행동을 조절하여 건강에 악영향을 줄 수 있다는 우려가 있다.

다른 나라들이 트라이엔에러를 겪으면 DTC에 대한 서비스와 산업을 키워나가고 있을때, 우리나라는 이에 대한 규제가 심해서 발전이 크게 없었다고 한다.

국내 허용된 검사항목은 위와 같고, positive 규제이다. positive 규제란 허용된 것 외에는 할 수 없다는 이야기이다.
반대인 negative 규제는 규정된 것 외에는 다 할 수 있다는 말이다.
따라서 우리나라는 위에서 허락된 유전자명 외에 다른 것은 검사할 수 없다. 따라서 더 주요한 인자들이 발견이 되었을때 이를 갱신할 수 없고 더 나은 서비스에 대한 발전이 없게 된다.
보면 알겠지만, 흥미로운 내용은 있지만 본인 건강에 치명적일 수 있는 내용은 거의 다 빠져있다.
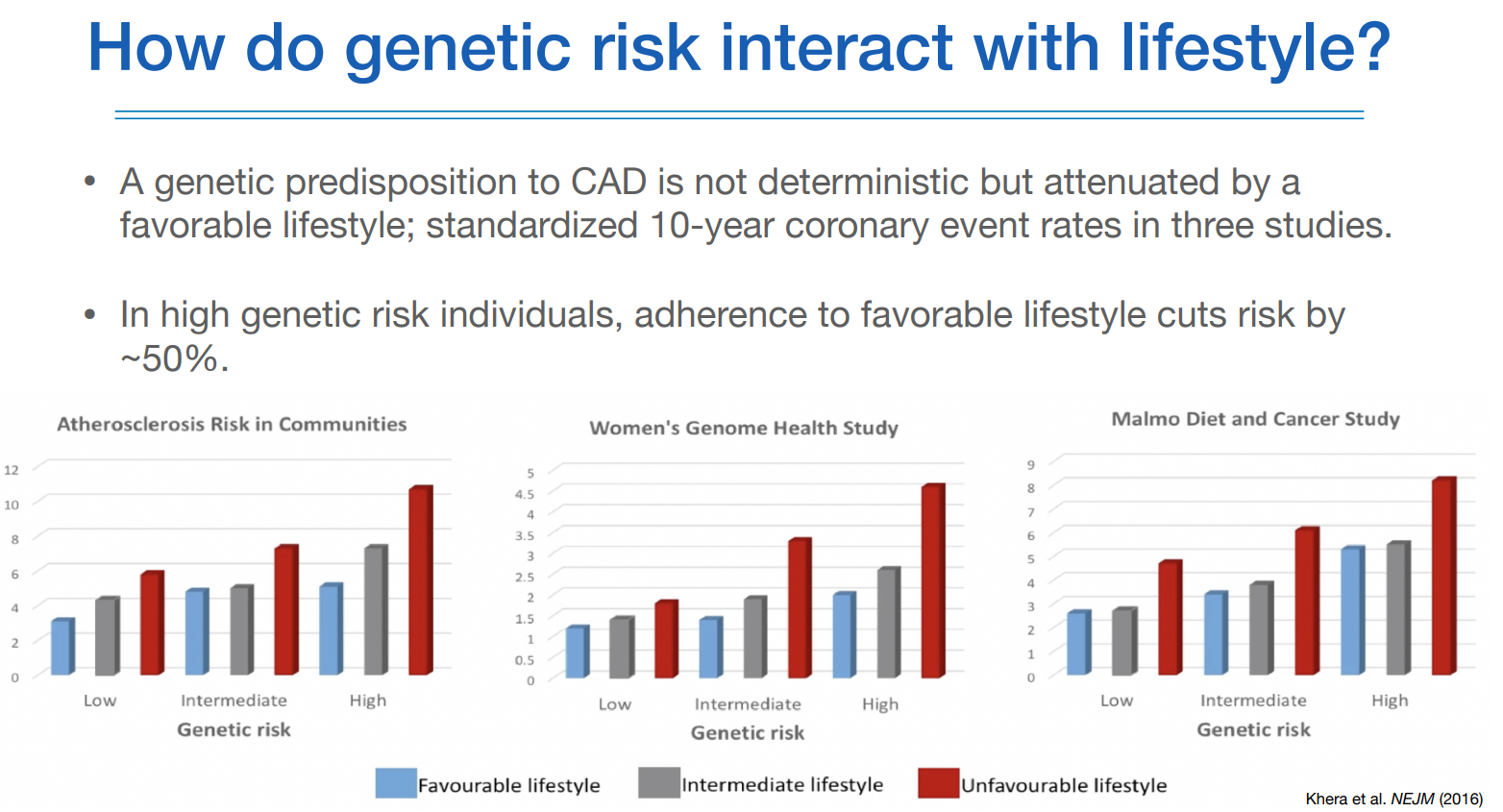
유전적 소인이 있을지라도 환경에 따라 위험도가 달라질 수 있음을 위 연구에서 보여주고 있다.
따라서 생활습관이 유전자를 극복할 수 있기 때문에, 유전적 요인이 밝혀졌더라도 너무 좌절할 필요는 없다.

GWAS 연구의 축적 덕분에 이런 예측이 가능하게 되었고, 이와 동시에 다양한 분석방법에 발전으로 예측력은 나날히 발전하고 있다.

끝!!
'medical' 카테고리의 다른 글
| [medical] 유전역학-개론, 8주차 암 유전체 연구 (0) | 2023.04.27 |
|---|---|
| [medical] 유전역학-개론 7주차, 유전자 변이에 대한 명명법 (0) | 2023.04.19 |
| [medical] 유전역학-개론 6주차, 차세대 시퀀싱(NGS) 데이터 분석 (1) | 2023.04.12 |
| [medical] 유전역학-개론 5주차, 유전체 시퀀싱 기술 (2) | 2023.04.05 |
| [medical] 유전역학-개론 4주차, 전장유전체 연관분석(GWAS) (2) | 2023.03.28 |



