
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- pytorch #torch #torch.nn #torch.nn.Functional #F #nn #차이
- 파이썬
- Phase recognition
- VNet #Vnet #segmentation #3D #voxel #semantic #pytorch #deep learning #UNet
- pytorch #torch #ViT #vit #VIT #Transformer #deep learning #vision #classification #image
- Surgical video analysis
- decorater
- nlp
- words encoding
- MICCAI
- TeCNO
- MRI
- monai
- 확산강조영상
- nibabel
- genetic epidemiology
- precision #정밀도 #민감도 #sensitivity #특이도 #specifisity #F1 score #dice score #confusion matrix #recall #PR-AUC #ROC-AUC #PR curve #ROC curve #NPV #PPV
- FLOPs #FLOPS
- parrec
- pytorch #torch #monai #dice #score #metric #segmentation #loss
- PYTHON
- 확산텐서영상
- 코드오류
- RGB #CMYK #DPI
- deep learning #segmentation #sementic #pytorch #UNETR #transformer #UNET #3D #3D medical image
- data augmentation #augmentation #3d #deep learning #image # medical image #pytorch #medical #CT #3D
- 유전역학
- 데코레이터
- tqdm #deep learning #dataloader #jupyter #notebook #ipywidgets
- nfiti
- Today
- Total
목록전체 글 (51)
KimbgAI
 [medical] 확산강조영상(Diffusion weighted image, DWI), 확산텐서영상(Diffusion tensor image, DTI) 란?
[medical] 확산강조영상(Diffusion weighted image, DWI), 확산텐서영상(Diffusion tensor image, DTI) 란?
확산강조영상(Diffusion weighted image, DWI)은 인체 내 물분자들의 자기 확산(self-diffusion) 정도를 정량화 함으로서 생체 조직의 생리학적 특성과 이상 유무를 판단하는 자기공명영상 기법의 한 종류이다. 생체 내 물분자의 움직임은 세포막 등에 의해 제약을 받는데, 이를 제한 확산(restricted-diffusion)이라고 한다. 확산이란 용액 내 용매 분자가 농도 경사에 의해 농도가 높은 곳에서 낮은 곳으로 이동하는 현상이다. 그러나 농도 경사가 없는 순수한 물에서도 물분자 자체가 가진 역학적 에너지에 의해 불규칙하게 움직이게 되는데, 이런 현상을 브라운운동 이라고한다. 물분자의 확산은 세포 밀도나 혐수성 세포막의 밀도가 높으면서 세포 외 공간의 왜곡이 심한 악성 조직에..
 [ML] 분류 평가 지표 정리(sensitivity, recall, precision, specificity, f1 score, NPV, PPV
[ML] 분류 평가 지표 정리(sensitivity, recall, precision, specificity, f1 score, NPV, PPV
분류 지표에는 Sensitivity, Precision, Specifisity, PPV, NPV 등.. 여러가지가 있습니다. 모델의 결과를 무엇에 중점을 두고 볼 것인가에 따라 다른 평가 지표를 사용해야하기 때문입니다. 하지만 늘 헷갈리고, 어렴풋이 알고있지만 이게 무엇을 의미하는지 제대로 이해하려면 멈칫하게 되는.. 그래서 한번 정리하고자 했습니다. 위 그림의 혼동행렬은 주의해서 봐야합니다. 어떤 곳에서는 True class와 Predicted class의 행렬이 뒤바뀌어있는 경우도 있습니다. 실제로 sklearn의 confusion matrix의 결과는 위 그림과는 반대로 행렬이 전치되어 나타납니다. 먼저 민감도. 민감도는 sensitivity, recall 으로도 불립니다. 실제 True 중에서 옳..
 [ML][pytorch] UNETR(21.03); UNEt TRansformers 코드 설명 및 구현
[ML][pytorch] UNETR(21.03); UNEt TRansformers 코드 설명 및 구현
UNETR(UNEt TRansformers)은 그 이름처럼 UNet 형태의 아키텍쳐이고, encoding 부분을 transformer 구조로 대체하여 feature map을 추출하는 것이 특징입니다. 본 내용은 UNETR 를 pytorch로 구현하는 것을 정리하였습니다. 핵심적인 부분인 ViT 구현을 아래 블로그(제 블로그 ㅎㅎ;;)를 참고하시면 더 자세하게 볼 수 있습니다. https://kimbg.tistory.com/31 [ML] ViT(20.10); Vision Transformer 코드 구현 및 설명 with pytorchAN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE https://arxiv.org/pdf/2..
 [ML] Data augmentation for 3D medical image
[ML] Data augmentation for 3D medical image
augmentation은 적은 데이터를 가지고도 데이터 풍부한 표현을 학습할 수 있는 장점이 있습니다. 그 중에서도 3D augmentation은 일반적인 2D augmentation과는 다른 특징들이 있는데, 이 글에서는 그와 관련된 내용을 담고 있습니다. monai, TorchIO 등 3D augmentation을 위한 라이브러리들이 몇몇 있지만, 여기서는 monai 기반 augmentation 적용 방법을 소개합니다. 본 내용은 아래 내용을 첨삭하여 작성했습니다. https://colab.research.google.com/github/Project-MONAI/tutorials/blob/main/modules/3d_image_transforms.ipynb 3d_image_transforms.ipyn..
 [ML] ViT(20.10); Vision Transformer 코드 구현 및 설명 with pytorch
[ML] ViT(20.10); Vision Transformer 코드 구현 및 설명 with pytorch
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE https://arxiv.org/pdf/2010.11929.pdf vit 논문에 관련한 양질의 리뷰는 상당히 많아서, 코드 구현에 관한 설명만 정리하고자 했습니다. 그래도 중요한 특징을 잡고 가자면, 1. 데이터가 많으면 많을수록 성능이 높아진다는 것. - ImageNet dataset과 같은 Mid-size으로 학습했을때, ResNet보다 성능이 좋지 않았지만, JFT-300M dataset으로 학습할 경우, ResNet보다 좋은 성능 달성함 - 이는 기존 CNN 계열의 모델보다 saturation이 덜 일어난다는 반증. - 하지만 일반적으로, 큰 데이터셋은 많이 없기때..
 [ML] Dice loss & Dice Score with monai, pytorch
[ML] Dice loss & Dice Score with monai, pytorch
Dice는 특이하게 loss function으로도 쓰이지만, metric으로도 사용된다. (그 이유는 segmentation이라는 task의 특수성 때문인데, pixel별로 class를 예측하기 때문에 metric score의 변화가 상당히 연속적이라 대부분의 구간에서 미분값이 유의미하기 때문이다.) (classification task에서 accuracy를 가지고 loss function으로 사용하지 않는 이유와 반대로 비슷하게 생각하면 된다.) 한편, 보통 Dice loss 는 1 - dice metric 으로 정의된다. 보시다시피 F1 score와 같다. 민감도(sensitivity)와 정밀도(precision)의 조화평균이다. monai에서 dice loss와 score를 편하게 계산할 수 있다...
결론부터 말하자면 이름처럼 torch.nn.functional은 함수고 torch.nn은 클래스이다. 그래서 torch.nn으로 구현한 경우에는 객체를 인스턴스화하여 attribute를 활용해 state를 저장하고 활용할 수 있고, torch.nn.functional로 구현한 경우에는 인스턴스화 시킬 필요 없이 바로 사용이 가능하다. *attribute란 클래스 내부에 있는 메소드나 변수 등을 의미함 그저 model class를 만들 때 init 부분에 torch.nn 클래스를 이용하여 모델을 정의해 버리거나 forward 진행할 때 직접 torch.nn.functional 함수를 이용하여 계산해주거나의 차이일 뿐! 출처 https://cchhoo407.tistory.com/29 https://cvml...
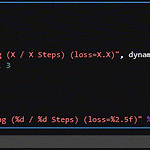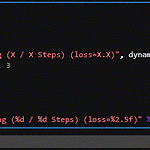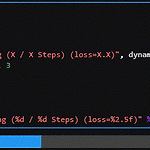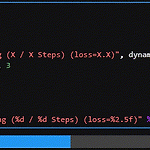 tqdm 활용 with dataloader
tqdm 활용 with dataloader
tqdm은 반복문에서 현재 어느 정도까지 진행이 되었는지 시각적으로 나타낼 수 있어 인내심을 길러주는데 아주 유용하다 특히나, pytorch에서 dataloader를 활용할때 자주 사용되는데, 여러 옵션을 넣어주면 더 편하게 볼 수 있어 좋다. from tqdm.notebook import tqdm import time dataloader = range(100) epoch_iterator = tqdm(iters, desc="Training (X / X Steps) (loss=X.X)", dynamic_ncols=True) global_step, max_iterations, loss = 0, 100, 3 for cnt, i in enumerate(epoch_iterator): time.sleep(0.1) ..
 FLOPs란? 딥러닝 연산량에 대해서..
FLOPs란? 딥러닝 연산량에 대해서..
논문들을 보고있노라면 FLOPs라는 개념이 등장하는데, 대충 연산량? 모델의 크기? 등 추상적으로 알고 있던 내용이라 정확한 개념을 알아보고자 정리를 해보았다.찾아보니 연산량에 대한 다양한 개념을 접할 수 있었다. FLOPs? FLOPS? MAC? 등.. 정리해보자 FLOPs(FLoating point OPerations)는 부동소수점 연산을 의미합니다. FLOPs에서의 연산은 사칙연산을 포함하여 root, log, exponential 등의 연산도 해당되며, 각각을 1회 연산으로 계산합니다. 반면, FLOPS는 FLoating point Operations Per Second의 약자로, 1초당 얼마나 많은 연산을 처리할 수 있느냐하는 하드웨어의 퍼포먼스 측면을 본다는 점에서 차이가 있습니다. MAC(M..
 [ML] VNet(16.06) 요약 및 코드 구현 (pytorch)
[ML] VNet(16.06) 요약 및 코드 구현 (pytorch)
V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation 논문은 아래 링크 참조 https://arxiv.org/abs/1606.04797 VNet은 UNet에서 영감을 받아 만들어진 architecture로써 구조가 상당히 비슷하다. CT나 MRI같은 image sequences data들은 2d보다 3d 그 자체로 분석했을때 유의미한 결과를 얻을 수 있는 부분이 많다. 왜냐하면, 어떤 한 slice 이미지가 직전, 직후 slice 이미지와의 연관성이 매우 높기 때문이다. 3d convolution은 이러한 장점을 가지고 연산할 수 있다. (연산량이 매우 많은 것은 단점..) 그림에서 볼수 있듯이, UNet과..
 RGB와 CMYK 차이
RGB와 CMYK 차이
### 이미지 관련 용어 ### 이는 색상모드를 의미함. RGB는 Red, Green, Blue로 이미지의 색상의 3개의 채널로 나타냄. 빛의 혼합방식과 동일. 이는 액정과 같은 디스플레이 매체에 적합함. 이미지를 불러들이면 해당 채널의 value가 높을수록 해당 채널의 색이 많다는 뜻임. 예를 들면, 아래 이미지에서 바다를 봤을때, 파란색 채널은 바다와 하늘이 밝게 보이는 반면 빨간색 채널은 어둡게 나타남. 반면, CMYK(Cyan, Magenta, Yellow, blacK)은 4채널로 물감의 혼합방식을 나타내며 섞일수록 어두워짐. 그래서 간판이나 인쇄물과 같은 출력물 작업에 적합함. 한편, 대표적인 해상도를 나타내는 척도로 dpi(dots per inch)가 있음. 1인치당 몇개의 도트(점)이 들어가..
 Brain MRI의 자동화된 segmentation을 위한 CAT12 사용법(CAT, Brainstorm, SPM)
Brain MRI의 자동화된 segmentation을 위한 CAT12 사용법(CAT, Brainstorm, SPM)
본 내용은 Brain MRI를 다양한 atlas로 segmentation을 해주는 tool에 대한 사용 설명을 담고 있습니다. CAT12를 사용하여 autometic하게 segmentation을 한 결과를 보시면.. 구성은 아래와 같습니다. A. CAT12이란? B. CAT12을 사용하기 위한 matlab 설치 C. Brainstorm 설치 (with SPM, CAT) D. CAT12 사용방법 E. 결과 확인 및 활용 A. CAT12이란? - CAT는 Computational Anatomy Toolbox의 약자로서, Brain image를 VBM (Voxel-based morphometry), DBM (Deformation-based morphometry), SBM (Surface-based morpho..
 Git, Github 시작 및 기초 명령어 정리
Git, Github 시작 및 기초 명령어 정리
글의 목적은 Github를 관리하고 활용하기 위해, 1. Repository 생성 2. Local repository와 Remote repository 연결 및 변경사항 저장 에 필요한 내용을 간단히 정리하였습니다. 1. Remote repository 생성 - (필수) Repository name 설정하기! - Description 생략 가능 - 공개하고 싶으면 Pubilc, 아니면 Private - Add a README file은 해당 repository에 대한 설명을 md(MarkDown) 형식으로 상세하게 담을 수 있는 파일이며, 나중에 수정할 수 있습니다. 2. Local repository와 Remote repository 연결 및 변경사항 저장 1) 원하는 경로 위에서 remote repo..
 github repository 삭제하기
github repository 삭제하기
1. Github에 로그인을 하고 해당 레파지토리에 접속 2. Settings 클릭 3. General -> Danger Zone의 Delete this repository 클릭 4. 삭제 확인을 위한 repository 주소 입력 후 활성화된 버튼 클릭 끝!
 [ML] U-Net(2015.05); Convolutional Networks for Biomedical Image Segmentation 요약 및 pytorch 코드 구현(2)
[ML] U-Net(2015.05); Convolutional Networks for Biomedical Image Segmentation 요약 및 pytorch 코드 구현(2)
U-Net에 대한 간략한 내용이 궁금하신 분은 지난 포스팅을 참고해주시면 되겠습니다~ https://kimbg.tistory.com/16?category=578326 [ML] U-Net(2015.05); Convolutional Networks for Biomedical Image Segmentation 요약 및 코드 구현 U-Net(2015.05); Convolutional Networks for Biomedical Image Segmentation 원문: https://arxiv.org/abs/1505.04597 본 리뷰는 Semantic Segmentation의 기술 동향을 살펴보며, 핵심 아이디어와 .. kimbg.tistory.com 1. 핵심 아이디어 구현 1) Using mirror padd..
 [ML] FCN(2014.11); Fully Convolutional Networks for Semantic Segmentation 요약 및 pytorch 코드 구현(2)
[ML] FCN(2014.11); Fully Convolutional Networks for Semantic Segmentation 요약 및 pytorch 코드 구현(2)
FCN 모델에 관련된 대략적인 내용은 아래 링크를 통해 확인하시면 되겠습니다. :) https://kimbg.tistory.com/15?category=578326 [ML] FCN(2014.11); Fully Convolutional Networks for Semantic Segmentation 요약 및 코드 구현 FCN(2014.11); Fully Convolutional Networks for Semantic Segmentation 원문: https://arxiv.org/abs/1411.4038 본 리뷰는 Semantic Segmentation의 기술 동향을 살펴보며, 핵심 아이디어와 Contributions을.. kimbg.tistory.com 본 내용의 구성은 다음과 같다. 1. FCN 구현 방법..
 [ML] STL10 Dataset 간편하게 다운받고 정리하기
[ML] STL10 Dataset 간편하게 다운받고 정리하기
오픈 데이터셋 중 CIFAR10(32x32)보다 고해상도의 간단한 Classification task를 위한 데이터셋을 찾다가 스탠포드에서 제공해주는 STL10이라는 데이터셋을 찾을 수 있었다. Data overview - train set: 5,000, test set: 8,000, unlabelled: 100,000 - 10 classes: airplane, bird, car, cat, deer, dog, horse, monkey, ship, truck - Images are 96x96 pixels, color - 500 training images per class (10 pre-defined folds) 데이터에 관한 더 자세한 내용은 아래 링크를 통해서 확인할 수 있다. https://ai.st..
 [ML] U-Net(2015.05); Convolutional Networks for Biomedical Image Segmentation 요약 및 pytorch 코드 구현(1)
[ML] U-Net(2015.05); Convolutional Networks for Biomedical Image Segmentation 요약 및 pytorch 코드 구현(1)
U-Net(2015.05); Convolutional Networks for Biomedical Image Segmentation 원문: https://arxiv.org/abs/1505.04597 본 리뷰는 Semantic Segmentation의 기술 동향을 살펴보며, 핵심 아이디어와 Contributions을 정리하고, 간단한 코드 구현을 통해 살펴보고자 한다. 아래 그림과 같이 architecture의 형태가 U자 모양을 하고 있어 U-Net이라고 네이밍되었다. U-Net은 FCN과 마찬가지로 skip architecture로 구성하여 feature map의 위치정보를 활용하였다는 점에서 FCN과 전반적인 구조는 크게 다르지 않기 때문에 architecture에 대한 내용은 그림으로 대체한다. 하지..
 [ML] FCN(2014.11); Fully Convolutional Networks for Semantic Segmentation 요약 및 pytorch 코드 구현(1)
[ML] FCN(2014.11); Fully Convolutional Networks for Semantic Segmentation 요약 및 pytorch 코드 구현(1)
FCN(2014.11); Fully Convolutional Networks for Semantic Segmentation 원문: https://arxiv.org/abs/1411.4038 본 리뷰는 Semantic Segmentation의 기술 동향을 살펴보며, 핵심 아이디어와 Contributions을 정리하고, 간단한 코드 구현을 통해 살펴보고자 한다. 주요 Contribution은 다음과 같다. 1. Fully convolutionalization - ILSVRC(Imagenet Large Scale Visual Recognition Challenge, 이하 이미지넷)에서 좋은 성적을 보였던 기존 CNN기반 모델(VGG)을 Backbone으로 구성하여 목적에 맞게 변형시켰다. - 이 과정에서 기존 ..
tensorflow를 주로 사용하다가 요즘 pytorch를 사용하려다보니 기본적인 것에서부터 정리가 필요하다고 느껴 남겨놓는다. pytorch에서 제공해주는 CrossEntorpyLoss function에는 softmax가 기본적으로 결합되어있기 때문에 model의 logit에 softmax를 따로 설정해주지 않아도 된다. 즉, torch.nn.CrossEntropyLoss() 은 torch.nn.LogSoftmax() 과 torch.nn.NLLLoss() 의 결합이다. 코드로 살펴보자 # CrossEntropyLoss 사용 (Class=3) import torch.nn as nn import torch from torch.nn import functional as F criterion = nn.Cros..